
Je ne sais pas comment fonctionne Gson en interne, mais si c'est comme XStream (un sérialiseur/désérialiseur de XML) les instanciations se font d'office via un constructeur 'vide' (même s'il n'existe pas) et les initialisations de champs se font par introspection sans passer par les setteurs.
Pour éviter les ennuis et les bricolages j'ai l'impression que c'est plus simple de passer par un Gson Instance Creator, comme conseillé ici https://futurestud.io/tutorials/gson...stance-creator (premier lien au pif trouvé sur Google).

Affichage des résultats 1 951 à 1 980 sur 5538
-
10/12/2018, 19h02 #1951Roxx0r


-
13/12/2018, 15h33 #1952Canardeur


- Ville
- Paris
Je viens de découvrir que ce code est valide avec MSVC
 :
:
La partie struct vers structured binding est valide en c++ 17.Code:struct { int a; double b; } test() { return { 1, 2.0 }; } int main() { auto[a, b] = test(); }
La partie importante ici est la structure anonyme définie en même temps que la fonction.
Je viens de voir que c'est plus une erreur de la part de l'équipe MSVC qu'autre chose mais que c'est en cours d'étude (Il me semble, je suis pas encore hyper à l'aise avec les proposals, TS et autres TR... )
Need cette fonctionnalité !
-
13/12/2018, 15h53 #1953:tournevis:

- Ville
- Blue team!
J'ai vaguement vu que les tuples avaient un support de plus en plus renforcé, mais là ça va plus loin encore?
Faut que je trouve le temps d'attaquer 14 et 17
-
13/12/2018, 17h38 #1954Highsc0re
C'est pas très différent d'un tuple au final. La seule différence c'est que tu nommes les membres mais que tu te retrouves avec un type anonyme (pas toujours très pratique, tu risques d'avoir besoin de std::invoke_result_t<test> à un moment). Envoyé par Raplonu
Envoyé par Raplonu

La proposition semble surtout réfléchir sur les problèmes posés par cette idée. Ça va prendre du temps pour avoir une réponse définitive.
@vectra, regarde au moins le C++14, c'est pas révolutionnaire mais ça améliore bien le C++11.
-
13/12/2018, 18h19 #1955Canardeur
- Ville
- Paris
C'est vraiment tout con, mais je trouve l'idée de voir le nom des membres directement dans la signature de la fonction apporte beaucoup en lisibilité et en productivité.
Avec un IDE, tu passes la souris sur la fonction et tu sais exactement comment prendre en charge ce qui est retourné.
L'idée d'utiliser une struct anonyme pousse le concept de : je renvois des choses qui n'ont pas vocation à rester ensemble. Si un nom représente bien ce que tu renvois et/ou que stocker le résultat tel quel a du sens, alors oui, c'est pas adapté.
L'exemple le plus simple qui me vient à l'esprit : un résultat et un code d'erreur :
Le cas classique, lourd à écrire avec un nom de type de retour à la noix. Il faut 2 étapes pour connaitre le contenu de ce que retourne get_size (Chercher le type de retour de la fonction, puis le contenu de ce type).
Léger à écrire mais il faut lire la doc pour savoir qui est qui.Code:struct HandleAndError { int handle; int error; }; HandleAndError get_handle();
Dans ce dernier cas, tu sais tout de suite qui est qui, et tu informes indirectement l'utilisateur de ne pas stoker la structure.Code:std::tuple<int, int> get_handle();
Code:struct { int handle; int error; } get_handle();FluteLa proposition semble surtout réfléchir sur les problèmes posés par cette idée. Ça va prendre du temps pour avoir une réponse définitive.
-
13/12/2018, 20h29 #1956Highsc0re
Pour le renvoi d'un résultat ou d'une erreur, il y a std::expected en projet (pas sûr que ce soit prêt pour C++20 malheureusement), et ça devrait être bien mieux avec les opérations sur les monades.
-
13/12/2018, 21h32 #1957*X86 ADV*
- Ville
- Vence
C++ va devenir aussi bien qu'OCaml

Faut absolument que je me mette à jour sur C++ j'ai un gros retard... Mes connaissances pré datent C++11. Vous connaissez de bons bouquins pour des gens niveau intermédiaire ?
-
13/12/2018, 22h09 #1958*X86 ADV*

- Ville
- Rive droite
Peu de chances, sans un cassage de backward compat' Envoyé par newbie06
") Sleeping all day, sitting up all night
Sleeping all day, sitting up all night
Poncing fags that's all right
We're on the dole and we're proud of it
We're ready for 5 More Years
-
13/12/2018, 22h57 #1959Tyranaus0r

- Ville
- Une chrysalide
J'ai du mal à voir l’intérêt de ces formalismes ... Envoyé par Raplonu
OK il y a un micro-gain de lisibilité dans le code, mais il est, je trouve très faible... n'est-ce pas de l'enculage de mouche ? (respectueusement bien sur)
Par exemple, le gain ne s'exprime pas si on a besoin de cette structure ailleurs (pour faire d'autres fonction du même type par exemple) et ou dans ce cas avoir une structure généraliste se vaut tout autant d'un point de vue lisibilité.
Le gain sur la lisibilité dans les autres cas, lui, est très situationnel, n'importe quel IDE qui se respecte te donne le contenu de ton HandleAndError en un clic ... et si le code est bien organisé la structure n'est pas loin ou dans un header avec un nom évident (genre gestion_erreur.h )
Enfin bon, il n'y a par contre que peu de raison que ce soit interdit, mais ça ne me donne pas trop envie de l'utiliser ^^.
-
14/12/2018, 00h04 #1960Canardeur
- Ville
- Paris
Oui, c'est très clairement un cas d'enculage de mouche. Mais c'est toute la beauté du C++, argumenter pendant 1000 ans sur des sujets que d'autres langages tranchent en 10 minutes (et finir avec des syntaxes du style obj.template call() Envoyé par Nilsou
 ).
).
Plus sérieusement, j'ai découvert ça aujourd'hui, et ça m'a refait penser au très bon talk de Kate Gregory où à 31 min elle aborde le sujet des fonctions avec plusieurs sorties.
Rapidement, ce qu'elle dit (ce que j'ai compris) :
Un nom te viens à l'esprit pour décrire ce que tu renvois ? -> À l'ancienne, on la déclare et on l'utilise.
Si ce que tu renvois n'est rien d'autre que 2 entiers ou 3 chaines de caractères et un entier -> tuple & strutured bindings.
Personnellement, je suis pas fan de cette dernière réponse ( À ceci près que cette solution est possible contrairement à ce que je propose ) . Et je trouve qu'une struct anonyme permet d'ajouter très facilement des informations extrêmement utiles sans perdre l'aspect strutured bindings.
) . Et je trouve qu'une struct anonyme permet d'ajouter très facilement des informations extrêmement utiles sans perdre l'aspect strutured bindings.
Je trouve qu'on peut mettre ça en relation avec les arguments d'une fonction. On préfère quoi ?Code:std::tuple<std::string, std::string, std::string, int> fun1(); struct { std::string name; std::string favoriteSinger; std::string bitCoinId; int captainAge; } fun2();
Code:void fun(std::string, std::string, std::string, int); void fun(NameAndFavoriteSingerAndBitCoinIdAndCaptainAge arg); void fun(std::string name, std::string favoriteSinger, std::string bitCoinId, int captainAge);
-
14/12/2018, 00h44 #1961Highsc0re
Il y a un lien entre le nom (de quoi ? de qui ?), le chanteur favori (de qui ?) et cet Id Bitcoin ? Je ne compte pas l'âge du capitaine qui devrait être une variable globale volatile, à moins que ce soit son age lors d'un évènement précis. Peut-être que ce lien mérite un nom, dans le type de retour ou dans le nom de la fonction. Si la fonction avait un meilleur nom, peut-être qu'on comprendrait le sens du tuple. C'est dur de discuter lisibilité sur des exemples bidons.
-
14/12/2018, 00h52 #1962Figure paternelle de substitution

Oui c'est pratique (ça existe en C#), ça évite de se faire chier à créer une struct dans certains cas, mais on ne s'en sert pas tous les jours.
D'autant que le jour ou tu veux renvoyer une information supplémentaire tu l'as dans l'os.
Enfin bref je ne suis pas hyper fan, mais on utilise de temps à autre. Et VS aide bien.
-
14/12/2018, 03h35 #1963Tyranaus0r
- Ville
- Une chrysalide
Le seul truc que je trouve sympa sur les tuple et cie, c'est pas du tout dans ce genre d'utilisation, mais plutôt en profitant des fonctions associées (notamment les opérateurs) qui permettent souvent de s'économiser du travail.
Genre si vous avez 3 entier a,b,c et 3 autres d,e,f et que vous voulez verifier que tout entier a,b,c est bien inférieur à tout les entiers d,e et f, ben il suffit décrire un truc comme tie(a,b,c)<tie(d,e,f) . En profitant du fait que les opérateurs sont déja écris ainsi (idem pour les égalités etc...)
En dehors de ça, j'ai un peu de mal à les utiliser, je trouve ça pas très propre, mais bon, chacun ses habitudes ^^.
-
14/12/2018, 16h24 #1964Canardeur
- Ville
- Paris
J'ai un exemple dans la std avec une méthode de std::map Envoyé par Cwningen
Le booléen représente quoi ? On doit lire la doc pour le savoir. Vrai et faux pour respectivement une insertion et un affectation. C'est pas incroyablement dur à comprendre mais le doute est permis.Code:template <class M> pair<iterator, bool> insert_or_assign(const key_type& k, M&& obj);
Je trouve cette solution élégante.Code:template <class M> struct {iterator it, bool insertSuccsess } insert_or_assign(const key_type& k, M&& obj);
PS : Juste, histoire d'être claire, je suis pas un défenseur de cette fonctionnalité. je trouvais juste cette solution intéressante et fait apparaitre un concept que je ne connaissais pas en programmation : le nommage des sorties.
-
14/12/2018, 17h06 #1965Highsc0re
Celui-là est bien mieux en effet. Par contre j'aurais appelé le booléen "inserted", puisqu'il n'indique pas la réussite de la fonction. C'est aussi à comparer avec "pair<iterator, bool> insert(P&& value)" où le type de retour est le même mais n'a pas exactement le même sens. Dans les deux cas, l'itérateur retourné est valide quand le booléen est faux, donc ce n'est pas remplaçable par un optional<iterator>. Pour insert, j'aurais du mal à nommer l'itérateur, il a un sens différent suivant la valeur du booléen : inserted_or_existing_iterator, ça fait un peu long. Ici la structure anonyme se justifie parce que c'est dur de l'expliquer autrement que par l’agrégation de ses deux membres. Mais lire la doc, ce n'est pas un mal, c'est parfois dur de bien expliquer les fonctions avec quelques noms courts.
Pour nommer les retours, il y a aussi la possibilité d'utiliser un pointeur/référence mutable en paramètre, ça se fait beaucoup en C. Par exemple, on peut imaginer: bool map_insert(map_t *map, void *value, map_iterator_t *position_out) (où position_out peut être nul si on n'est pas intéressé). Mais je ne crois pas que ce soit un style très apprécié en C++.
-
14/12/2018, 19h59 #1966Roxx0r

Je te remercie de Googler pour moi ... Envoyé par William Vaurien
 (j'avais trouvé ces vidéos, mais pas celle-ci en particulier, je m'y remets...)
(j'avais trouvé ces vidéos, mais pas celle-ci en particulier, je m'y remets...)
-
18/12/2018, 12h49 #1967Tyranaus0r
Rien à voir (ou de très loin) avec le dev, mais je me suis dit que ce petit hommage à tous nos sysadmin préférés, qui font en sorte que notre code puisse
plantertourner 24/24 méritait bien un détour ici
Ce qu'il faut savoir, c'est qu'on ment beaucoup aux minmatars, surtout lorsqu'ils posent des questions du style: "t'es sûr que ça vole, ce truc ?" Cooking Momo, le 30/08/09
-
18/12/2018, 18h20 #1968Z'oeuf

excellent
-
23/12/2018, 13h42 #1969Tyranaus0r

- Ville
- Auxerre, 89
Quand les amibes résolvent le problème du vendeur itinérant de manière linéaire:

An Amoeba Just Found an Entirely New Way to Solve a Classic Computing Problem
(Amoeba = amibe)
-
23/12/2018, 14h38 #1970:tournevis:
- Ville
- Blue team!
Et on comprend également l'origine de agar.io (perso j'avais pas saisi).
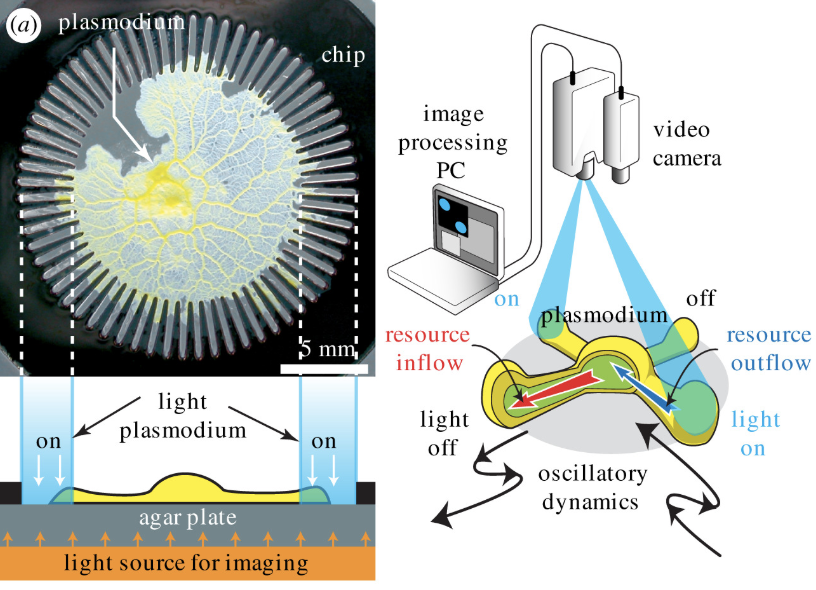
-
23/12/2018, 17h35 #1971Tyranaus0r
- Ville
- Une chrysalide
C'est cool, mais on dit "Problème du voyageur de commerce" en français Envoyé par FB74
Et sinon des trucs comme Kohonen trouvaient des solutions acceptable de façon linéaire également non ?
-
24/12/2018, 12h14 #1972Tyranaus0r
- Ville
- Bordeaux
Je n'ai pas regardé l'article original, seulement le site sciencealert linké, mais ils disent bien que l'amibe ne trouve pas un chemin optimal, seulement "presque optimal" - ce qu'on sait faire, il y a de bons algorithmes d'approximation pour le TSP quand on a l'inégalité triangulaire, et un schéma d'approximation dans le cas euclidien. En pratique de l'algo de premier cycle universitaire permet d'obtenir en temps linéaire(*) un chemin qui ne fait pas plus du double de l'optimal (et bien mieux que ça dans la plupart des cas pratiques). Bon, ce n'est pas du biocomputing, et ça demande une vision globale du terrain.
Je connaissais la bestiole du même genre qui résolvait les labyrinthes (de la bouffe en deux points et des chemins légèrement répulsifs pour l'inciter à trouver le chemin le plus court), c'est du même acabit ici. Et les images que j'avais vues me semblaient plus impressionnantes, là ils ne sont pas allés au delà de 8 points.
(*) Temps linéaire truandé, pour être honnête.
-
24/12/2018, 18h25 #1973Tyranaus0r

- Ville
- Irem
Ce n’est pas le truc magnifique mais complètement impossible à faire tourner car il demande une quantité de RAM délirante ? Envoyé par Nilsou
une balle, un imp (Newstuff #491, Edge, Duke it out in Doom, John Romero, DoomeD again)
Canard zizique : q 4, c, d, c, g, n , t-s, l, d, s, r, t, d, s, c, jv, c, g, b, p, b, m, c, 8 b, a, a-g, b, BOF, BOJV, c, c, c, c, e, e 80, e b, é, e, f, f, f, h r, i, J, j, m-u, m, m s, n, o, p, p-r, p, r, r r, r, r p, s, s d, t, t
Canard lecture
-
24/12/2018, 20h31 #1974*X86 ADV*

C'est vrai qu'ils auraient pu mieux faire, ils auraient au moins pu proposer un algo qui trouve une solution optimale en temps constant pour tout n≤8. Envoyé par Shosuro Phil

-
24/12/2018, 21h24 #1975Tyranaus0r
- Ville
- Auxerre, 89
-
25/12/2018, 22h54 #1976Tyranaus0r
- Ville
- Bordeaux
De toute manière on est bien d'accord, toutes les expériences concrètes de temps d'exécution d'algos sont pipeau vu qu'elles ne portent que sur des instances de taille bornée. Parfois faut avoir l'esprit un peu ouvert...
-
31/12/2018, 11h54 #1977*X86 ADV*

- Ville
- Nord de France
Loin de moi l'idée d'être un expert mais afin de donner un peu de vie au topic, je tente un partage. N'hésitez pas à donner vos avis
.
D'après Packt (donc ça vaut ce que ça vaut... Même si je suis fan de leur ebook gratuit, c'est pas forcément les mieux placés pour ce type d'article.)
En 2019 :
1) Python
2) Go
3) Rust
4) TypeScript
5) Scala
6) Swift
7) Kotlin
8) C
Je ne sais pas vraiment quoi en penser... Je ne suis pas surpris pour Python car clairement on en entend tellement parler dans beaucoup de domaine et la facilité à pondre ces premières lignes de code en font un super outil pour démarrer le développement / devenir développeur tout court :D .
Je suis un peu surpris par le C qui je pense est un langage vieillissant même si très performant. J'en ai fais que à la fac mais dans le monde professionnel, il y a quelques années quelques clients avaient des batchs en C sur des serveurs Linux mais je croise de plus en plus d'autres solutions pour les traitements de type Batch chez les clients du coin donc je le pensais en déclins...
Je n'ai par contre, jamais touché les autres langages (même si GO m'a longtemps fait de l'oeil).
 Envoyé par Kazemaho
Envoyé par Kazemaho
-
31/12/2018, 12h31 #1978Tyranaus0r
- Ville
- Bordeaux
Mais c'est censé être un classement de quoi? On manque d'infos...
-
31/12/2018, 12h42 #1979*X86 ADV*
- Ville
- Nord de France
Des langages à apprendre Envoyé par Shosuro Phil
") . Dans l'article il y a les raisons de pourquoi les apprendre ou non .
Envoyé par Kazemaho
. Dans l'article il y a les raisons de pourquoi les apprendre ou non .
Envoyé par Kazemaho
-
31/12/2018, 13h34 #1980Roxx0r

- Ville
- 3/10
Un minimum de C me semble être indispensable. Il fait office de glue, c'est difficile de s'en passer si on veut utiliser une bibliothèque X avec un langage Y.
Rien ne me choque moi, je suis un scientifique ! - I. Jones

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non