
Istanbul vs Nehalem sur LINPACK: http://www.advancedclustering.com/co...eron-2400.html

Affichage des résultats 781 à 803 sur 803
Discussion: K10 et innovations
-
26/06/2009, 13h19 #781*X86 ADV*

- Ville
- Vence
-
26/06/2009, 13h55 #782*X86 ADV*

Mmmh, pas mal, l'efficacité d'Istambul n'est "que" de 7 points en deçà de Nehalem.
Ils n'ont pas inclus la conso de la plateforme par contre, et là Intel avec son process et seulement 4 cores doit être bien devant. Ca peut influer sur le ratio $ / GFLOP, même si 15$, ca parait assez difficile à rattraper (pour du quad vs hexa).
-
26/06/2009, 14h30 #783*X86 ADV*
- Ville
- Caribou fondu
Sauf erreur de ma part Istambul consomme moins que Nehalem quad
")

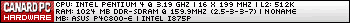
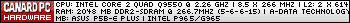
-
26/06/2009, 14h40 #784*X86 ADV*
Fb-dimm ?
(edit : Ben nan, même pas)
-
26/06/2009, 14h49 #785*X86 ADV*
- Ville
- Vence
Attention quand meme : la lib math kernel d'Intel a ete grandement optimisee pour i7 assez recemment. Donc selon la version qu'ils ont utilisee pour leur benchmark, ca pourrait changer les resultats de maniere assez radicale.
-
26/06/2009, 21h41 #786Canardeur
- Ville
- Nanterre (92...)
C'est normal, les Xeon ont un TDP inférieur à leur équivalent desktop [80W contre 95], ils doivent être sélectionnés beaucoup plus rigoureusement, un peu comme les extrem [et Athlon FX], voilà ce qui rends les CPU pour serveurs beaucoup plus chers, avec aussi le fait qu'ils doivent s'acheter en beaucoup moins grosse quantité vue le faible taux d'acheteurs. Envoyé par Oxygen3
Envoyé par Oxygen3



-
28/06/2009, 00h17 #787*X86 ADV*
- Ville
- Caribou fondu
Mouais, reste à voir ce qui est réellement vendu par les IBM/HP. Envoyé par lordmagnum
Car : L=60W
E=80W
X=95W
W=130W
-
04/09/2009, 23h20 #788*X86 ADV*

http://www.hardware.fr/news/10392/12...ous-cpu-z.html
J'imagine que les 10 Mo de L3, c'est parce que l'HT-Assist bouffe 1 Mo par die.
-
05/09/2009, 11h04 #789*X86 ADV*

Gagné. Envoyé par Alexko
")

Edit: par contre le "96-way", ça me parait louche...Dernière modification par Møgluglu ; 05/09/2009 à 11h10.
-
05/09/2009, 12h28 #790*X86 ADV*
Hum sur Shanghai c'est 48-way, donc logiquement c'est pareil sur Istanbul et ça passe à 96 sur Magny-Cours, mais effectivement s'il ne détecte que 10 Mo c'est étonnant.
-
05/09/2009, 14h36 #791*X86 ADV*
Effectivement. Vu que c'est une config mono-socket, double-die, il ne devrait pas y avoir besoin de probe filter et donc le/les L3 devraient bien faire 12 Mo avec 96 voies.
Et en multi-socket (>=2?) on devrait avoir 10 Mo avec 80 voies...
Probablement un problème de bios ou de détection...
-
05/09/2009, 16h43 #792*X86 ADV*
Non c'est du dual-socket, cf. Le reste ici : http://www.xtremesystems.org/forums/...d.php?t=233565
Du coup ça fait 4 dies donc il est logique que l'HT-Assist soit activé.
-
08/09/2009, 23h38 #793*X86 ADV*
- Ville
- Caribou fondu
Amusant, personne ne parle du i5
En revanche, j'ai été très supris (dans le bon sens du terme) de voir le gain de perfs du PhenomII entre le 32bits Vista et le 64bits 7 ... Presque 5 à 10%, et ca lui permet de venir titiller les plus rapides Quad Penryn, c'est plutot pas mal !
-
08/09/2009, 23h42 #794*X86 ADV*
- Ville
- Vence
Je boycotte Intel et sa valse des sockets.
Pour le 64-bit chez AMD, je ne suis qu'à moitié étonné : ils ont fait un vrai effort, pas comme les "autres" qui n'ont été que des suiveurs sur ce coup-là, alourdis par un souci initial de schyzophrénie itanesque.
-
09/09/2009, 00h53 #795*X86 ADV Natif*

- Ville
- Far far away
Tu risques de boycotter un moment. De toutes facons on a deja eu cette conversation, ce n'est pas comme si tu allais upgrader ton CPU sans changer la carte mere . C'est pour le principe !
---------- Post ajouté à 01h53 ----------
Oui, les ameliorations dans le frontend de Nehalem deviennent visible avec le passage au 64 bits. Le fait que le passage au 64bits se soit fait si tard a serieusement desavantage AMD qui avait une archi efficace sur du code 64bits depuis longtemps... Envoyé par Oxygen3
Ca me rappelle un peu la sortie du PPRO, qui n'etait pas vraiment mieux que le pentium sur du code 16 bits. Tout le monde achetait du pentium jusqu'au jour ou le code 32 bits a pris le dessus. Pareil pour core2/corei7, avec le passage au 64 bits, les offre core2 vont commencer a se faire vieille...sfefe - Dillon Y'Bon
-
11/02/2010, 11h48 #796*X86 ADV*
- Ville
- Liège (Belgique)
http://www.semiaccurate.com/2010/02/...nm-llano-core/
Toujours pas de grosse amélioration du core (K10 based en gros)... dommage.
-
11/02/2010, 12h58 #797*X86 ADV*
- Ville
- Vence
Ca n'aurait pas été casse-gueule de faire à la fois l'intégration du GPU et le changement de process et de gros changements de micro-architecture en une fois ?
-
11/02/2010, 13h45 #798*X86 ADV*
Pour une architecture en fin de vie, je trouve que c'est déjà pas mal. Je ne m'attendais pas à tant que ça... D'un autre côté, AMD a sans doute utilisé Llano pour se faire la main sur certains trucs surtout destinés à être dans Bulldozer. Envoyé par DJ_DaMS
-
11/02/2010, 18h55 #799*X86 ADV Natif*
- Ville
- Far far away
C'est pas comme si le core n'avait pas ete touche. Changer la taille des buffers force toujours a pas mal de changements locaux pour maintenir tes timings, un meilleur diviseur est un bout de hardware pas particulierement simple. En gros ce qui est decrit la est l'equivalent du passage de Merom a Penryn, voir meme un peu plus. Des fois il n'y a pas besoin de changer la micro architecture quand tu peux juste corriger toutes les petites inefficacites du projet precedent.
fefe - Dillon Y'Bon
-
11/02/2010, 20h24 #800*X86 ADV*
Et puis la latence des instructions FP aurait été réduite, ce qui suivant de quelles instructions on parle peut être un changement conséquent...
Même si je vois mal AMD faire des modifs importantes à une FPU qui n'a quasiment pas changé depuis 10 ans, alors qu'une version totalement nouvelle pour Bulldozer est dans les cartons.
À moins que ce soit justement à titre expérimental pour avoir un retour avant Bulldozer, mais ça serait un peu risqué pour une expérience...
-
11/02/2010, 21h18 #801*X86 ADV Natif*
- Ville
- Far far away
Ca peut etre pour les instructions microcodees qui peuvent maintenant utiliser la logique du divider et devaient utiliser des rounds de mul-add avant. C'est ce sur quoi je parierais.
fefe - Dillon Y'Bon
-
11/02/2010, 21h39 #802*X86 ADV*
Du genre, la division/racine carrée flottante qui utiliserait le diviseur matériel pour avoir une meilleure approximation initiale et faire moins d'itérations? Ou bien carrément un diviseur hardware complet?
Récemment on a aussi vu passer des papiers de gens sponsorisés par AMD sur l'utilisation d'une unité dédiée d'élévation au carré (de latence largement inférieure à celle d'un multiplieur) pour accélérer la division par convergence...Dernière modification par Møgluglu ; 11/02/2010 à 21h44.
-
23/02/2010, 14h14 #803Hardc0re

- Ville
- LIEGE
Il semble que la livraison des opterons "Magny-Cours" a débuté .
De 1,5 à 2,4 Ghz en octocore et de 1,9 à 2,2 Ghz en dodécacore ,tous avec 12Mo de L3 et 115W de TDP .
Et un controleur DDR3 sur 4 canaux (nouveau socket) ,à voir au niveau perf en multi s'il y a eu d'autre amélioration au niveau archi
Edit : confirmation sur le blog AMDDernière modification par Lionel33 ; 23/02/2010 à 14h21.

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non