
Quoi, y'a pas que des interventions à l'arrache entre 2 réu sur ce forum ?Envoyé par Nattefrost


Affichage des résultats 901 à 930 sur 5502
-
15/03/2018, 15h04 #901Highsc0re


Attention, un Max_well peut en cacher un autre
Equipe Highlander La Rache
-
15/03/2018, 17h04 #902Tyranaus0r

- Ville
- Paris
Bah y'a moyen de dire que t'aimes pas sans balancer le truc que je dénonçais comme absolu "je veux zéro abstraction" alors que ça veut pas dire grand chose. Envoyé par Nattefrost
Cela dit t'as pas tort même en exagérant le trait, je pense que si tout le monde commençait ses phrases comme ça sur le oueb quand c'est applicable, le monde serait meilleur
- - - Mise à jour - - -
Non moi c'est calme, posé et réfléchi pendant les 5h de repos entre les deux réunions du jour Envoyé par Max_well

-
15/03/2018, 18h12 #903Roxx0r

- Ville
- 3/10
Moi, j'avais répondu pendant une réunion.
Rien ne me choque moi, je suis un scientifique ! - I. Jones
-
15/03/2018, 18h28 #904*X86 ADV*

- Ville
- Rive droite
La seule méthode valable. Envoyé par Helix
Sleeping all day, sitting up all night
Poncing fags that's all right
We're on the dole and we're proud of it
We're ready for 5 More Years
-
15/03/2018, 19h40 #905*X86 ADV*

- Ville
- Laincanard
Comment on fait si on n'a pas de réunions ?

-
15/03/2018, 20h24 #906Tyranaus0r

Organises en une avec ton rubber duck Envoyé par taronyu26

-
15/03/2018, 21h37 #907*X86 ADV*
- Ville
- Laincanard
J'ai pas ça sous la main Envoyé par Nattefrost

-
16/03/2018, 16h33 #908Hardc0re

- Ville
- Lyon
J'arrive un peu après la bataille mais ouais, belle trouvaille. Envoyé par rOut
"Nobody exists on purpose. Nobody belongs anywhere. We're all going to die. Come watch TV." - Morty Smith
-
16/03/2018, 20h47 #909Roxx0r


- Ville
- CaribouLand
-
16/03/2018, 21h07 #910Tyranaus0r

- Ville
- Un petit canard.
 C'est la faute à Arteis
C'est la faute à Arteis
-
19/03/2018, 15h04 #911Figure paternelle de substitution

docker run --> Marcel chauffe
-
26/03/2018, 11h17 #912Tyranaus0r
- Ville
- Un petit canard.
C'est la faute à Arteis
-
26/03/2018, 12h05 #913Roxx0r
- Ville
- 3/10
Dans le même genre, il y a ça : https://www.levenez.com/lang/
C'est un graphe de l'évolution des langages, on arrive assez bien à y suivre les liens entre eux. Même si il n'y a pas tout.Rien ne me choque moi, je suis un scientifique ! - I. Jones
-
26/03/2018, 14h29 #914*X86 ADV*

Merci, ça fait longtemps que je cherchais ce lien qui avait été posté dans un des topics précédents (l'original, pas la copie moins drôle) : http://james-iry.blogspot.fr/2009/05...wrong.html?m=1 Envoyé par Orhin
Je me rappelais de ce passage :
1990 - A committee formed by Simon Peyton-Jones, Paul Hudak, Philip Wadler, Ashton Kutcher, and People for the Ethical Treatment of Animals creates Haskell, a pure, non-strict, functional language. Haskell gets some resistance due to the complexity of using monads to control side effects. Wadler tries to appease critics by explaining that "a monad is a monoid in the category of endofunctors, what's the problem?"
-
27/03/2018, 00h01 #915Tyranaus0r
- Ville
- Bordeaux
1972 - Dennis Ritchie invents a powerful gun that shoots both forward and backward simultaneously. Not satisfied with the number of deaths and permanent maimings from that invention he invents C and Unix.
-
27/03/2018, 12h11 #916Tyranaus0r

- Ville
- faquin !
the Capitalization Of Boilerplate Oriented Language (COBOL)"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
28/03/2018, 05h26 #917Roxx0r

- Ville
- FR
Canards programmeurs, je bute actuellement sur un problème de complexité.
Etant donné Nf objets d'une certaine classe tous paramétrés par le même un entier N, je me retrouve à assembler une matrice P de taille 3x3 nécessitant la bagatelle de Np = Nf * N^8 additions matricielles.
C'est à dire que la matrice P peut être écrite comme P = somme[i = 1;Np] ( P_i ), avec Np = Nf * N^8.
Np est de l'ordre de 10,000 et N = 6 généralement, soit Np = 16 milliards d'additions matricielles.
J'ai jusqu'à présent eu recours à OpenMP pour paralèlliser tout ça sur 24 threads, mais je ne suis pas satisfait du résultat.
Je songeais à me tourner vers du GPU computing pour aborder le problème, mais je n'ai aucune familiarité avec le domaine. J'ai trouvé deux-trois tutoriels ici ou là, mais rien qui ne me semble très formel ou suffisamment proche de ce que je cherche à faire. Ah, et quid de la différence entre OpenCL et CUDA?
Merci pour vos lumières!Dernière modification par BentheXIII ; 28/03/2018 à 05h45.
Envoyé par Colargol
-
28/03/2018, 09h16 #918*X86 ADV*
Comment sont calculés tes P_i ?
A priori ton problème n'est pas que tu as 16 milliards d'additions, c'est que tu as 16 milliards de matrices en mémoire.
CUDA est le toolkit propriétaire de Nvidia qui ne fonctionne que chez Nvidia mais qui le fait très bien. Envoyé par BentheXIII
OpenCL est un standard poussé par Apple et AMD, plus ou moins portable, mais les fonctionnalités et la perf sont très dépendante de l'implèm de chaque constructeur (pour rester diplomate). Naturellement, Nvidia supporte le minimum vital de l'OpenCL d'il y a 10 ans sans faire aucun effort pour ne pas cannibaliser CUDA.
-
28/03/2018, 10h25 #919*X86 ADV*
- Ville
- Rive droite
Ca prend combien de temps dans ton implem actuelle ?
Sleeping all day, sitting up all night
Poncing fags that's all right
We're on the dole and we're proud of it
We're ready for 5 More Years
-
28/03/2018, 13h05 #920Tyranaus0r
- Ville
- faquin !
Pour une transition sans trop de douleur, tu peux partir sur OpenACC qui est une adaptation des principes d'OpenMP aux GPUs.
Ou même faire directement du OpenMP sur GPU avec les directives target apparues depuis la 4.0 mais je trouve la syntaxe plus lourde.
Mais bon le problème de fond c'est surtout de devoir faire des milliards de simples additions, avec une valeur lue pour chaque addition.
Sur de grandes quantité de données comme ça, le temps pour lire une valeur en mémoire est beaucoup plus long que le temps de faire l'addition, c'est avant tout le débit mémoire qui va fixer la limite des performances. Tu as sûrement eu un gain en parallélisant sur les premiers coeurs car un coeur seul ne peut pas forcément exploiter tout le débit de la mémoire mais un fois le débit de lecture saturé c'est fini.
Passer sur GPU ne changera rien vu qu'il faudra de toutes façons lire ces valeurs en mémoire pour les envoyer sur le GPU.
Si il n'y a aucune localité des données, que ce calcul est du one-shot et que les miyards de matrices à sommer ne servent plus à rien après, tu es dans une impasse.
Une voie de sortie serait de paralléliser sur plusieurs machines (MPI) si c'est possible, dans ce cas le débit mémoire sera multiplié par le nombre de machines. Mais il faut que les sous-groupes de matrices à sommer puissent être lues/construites indépendamment, sinon tu vas juste déplacer le goulot d'étranglement au niveau du réseau.
Sinon 16 milliards de matrices 3x3, en float simple précision ça fait la bagatelle de 576 Go de mémoire. Tu en as suffisamment pour tout stocker ? A voir si il n'y aurait pas du swap sur disque qui ralentirait fortement le tout..."Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
28/03/2018, 17h42 #921Roxx0r
- Ville
- FR
Merci à tous pour vos réponses! Tout d'abord, je n'ai pas 16 milliards de matrices P_i stockées en mémoire. Ces matrices sont elles mêmes assemblées en fonction de l'indice i et de paramètres liés au N_f objets.
Voici l'expression que je cherche à calculer
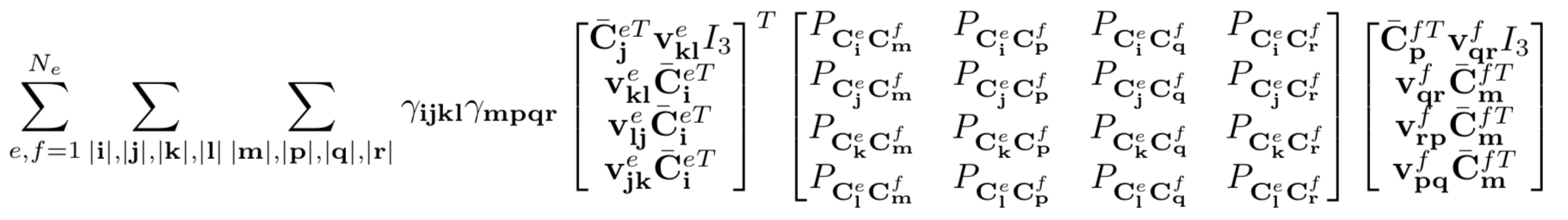
- e et f font références à des indices d'éléments surfaciques. Notez que la complexité de cette somme est de l'ordre de N_e, et pas N_e ^2 car toutes les paires (e,f) ne font pas sens et certaines sont donc exclues au préalable
- i, j, k, m, p, q et r sont des triplets d'indices, c'est à dire que i se lit par exemple (i,j,n-i-j) où n est une constante. Les sommes ci-dessus sont effectuées sur toutes les combinaisons de i telles que | i | = n. Pour n = 1, on a par exemple (100), (010) et (001).
- les coefficients gamma_ijkl * gamma_mpqr sont calculés au préalable
- Il y a 8 sommes imbriquées sur les triplets d'indices, d'ou le ^8 dans l'approximation que j'avais donné plus haut
- Les matrices de taille 12 x 3 ainsi que la matrice centrale de taille 12x12 sont fonctions des éléments surfaciques et de la combinaison des triplets d'indices
quant à l'implémentation actuelle, elle tourne encore après 11 h (70% effectués environ) . Je vais explorer des pistes analytiques pour limiter la complexité du calcul ...
(70% effectués environ) . Je vais explorer des pistes analytiques pour limiter la complexité du calcul ...
Dernière modification par BentheXIII ; 28/03/2018 à 19h49.
Envoyé par Colargol
-
28/03/2018, 18h40 #922*X86 ADV*
Cette foire aux indices.

À vue de pif tu as effectivement moins de 10^12 opérations. Idéalement, ça devrait prendre quelques secondes sur un seul CPU multicœur moderne. 11h, c'est vraiment beaucoup. Il y a 2 ou 3 ordres de grandeur à rattraper avant de commencer à penser à passer sur GPU ou cluster. C'est codé comment pour l'instant ?
-
28/03/2018, 19h06 #923Roxx0r
- Ville
- FR
En c++ avec Armadillo pour les opérations vectorielles/matricielles, et OpenMP pour paralléliser la boucle externe. Y'a surement des redéclarations inutiles et autres bétises
 .
Envoyé par Colargol
.
Envoyé par Colargol
-
28/03/2018, 19h17 #924*X86 ADV*
Tu ne déclares ou alloues rien dans la boucle interne ? Armadillo alloue dynamiquement la mémoire pour ses objets, même si les opérations ne sont pas chères les coûts de construction/destruction peuvent être très lourds. Sans voir le code, mon expertitude CPC s'arrête là.
-
28/03/2018, 19h41 #925Tyranaus0r
- Ville
- faquin !
Envoyé par BentheXIII

Gé ri1 kompri"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
28/03/2018, 20h02 #926*X86 ADV*
- Ville
- Rive droite
Ouaip à mon avis en c++ rapide single threadé, ça devrait être beauuuuuuuuuuucoup plus rapide avant d'aller plus loin.
Sleeping all day, sitting up all night
Poncing fags that's all right
We're on the dole and we're proud of it
We're ready for 5 More Years
-
28/03/2018, 21h15 #927Roxx0r
- Ville
- FR
J'ai recompilé mon programme avec -g et l'ai profilé avec Instruments. Armadillo semble coupable, mais plus au niveau de l'exécution des opérations que à la construction/destruction ...
Envoyé par Colargol
-
29/03/2018, 01h13 #928Caneton
Salut,
Je cherche à optimiser un de mes algo (écrit en C# par contrainte d'intégration) et plus particulièrement une boucle for. L'algo cherche à étendre un arbre au fur et à mesure que les données arrivent et ensuite à calculer certains chemins (un peut comme du Drikstra).
Mon arbre est simplement une liste de liste que je fais grossir quand j'ai des données qui arrivent:
ligne 1: for (int n=0;n<nombre d'arborescences dispo;n++)
ligne 2: {
ligne 3:
ligne 4: Arbre.Add(branch1)
ligne 5: Arbre.Add(branch2)
ligne 6: Arbre.Add(branch3)
ligne 7: }
J'ai remarqué que le temps d'excétution entre ligne 7 et ligne 3 est du meme ordre de grandeur que celui entre ligne 4 et 6. C'est à dire que le temps que met mon ordi à reboucler (c'est un simple GOTO?) est aussi long que le temps pour faire les calculs. Ca me semble un peu bizarre, car je pensais que le rebouclage devait etre instantané. Vous avez une explication?
Question subsidiaire: vaut-il mieux allouer la mémoire avant la boucle, plutot que de faire des Add? En d'autres termes, faire un gros arbre/allouer des branches/couper des branches vs. partir d'un petit arbre/ajouter des branches.
Merci beaucoup!
-
29/03/2018, 09h28 #929*X86 ADV*
- Ville
- Rive droite
C'est impossible d'en dire plus en remote comme ça. Instruments il sample des callstacks ou juste des fonctions ? Envoyé par BentheXIII
Sleeping all day, sitting up all night
Poncing fags that's all right
We're on the dole and we're proud of it
We're ready for 5 More Years
-
29/03/2018, 10h03 #930*X86 ADV*
Il est impossible d'assigner un temps d'exécution à une ligne de code en particulier, parce que le processeur traite une ou deux centaines d'instructions simultanément. Dans la boucle, il va commencer à traiter les instructions plusieurs itérations à l'avance avant d'avoir fini l'itération courante. Envoyé par Dr.Kant
Là ton profiler doit simplement mesurer le temps d'exécution de la boucle entière ou de la fonction, et diviser le temps obtenu par le nombre d'instructions ou même le nombre de lignes de code. Les temps affichés n'ont pas de sens physique à cette granularité.
Si tu as des infos a priori sur la forme de ton arbre, tu as intérêt à le pré-allouer, ou même utiliser un layout mémoire spécialisé (du genre mettre en bijection les coordonnées des nœuds d'un arbre binaire avec un index dans un vecteur). Sinon, il te faudra un allocateur dynamique de toute façon, mais il doit toujours y avoir moyen d'optimiser dans les coins, par exemple en allouant les 3 branches en une fois.Question subsidiaire: vaut-il mieux allouer la mémoire avant la boucle, plutot que de faire des Add? En d'autres termes, faire un gros arbre/allouer des branches/couper des branches vs. partir d'un petit arbre/ajouter des branches.
") .
.
 Répondre avec citation
Répondre avec citation

 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non