
Il me semblait pourtant que Bulldozer avait plus de capacité de décodage qu'Istanbul (tant qu'on reste en single thread) ?Envoyé par Doc TB

http://www.realworldtech.com/bulldozer/5/

Affichage des résultats 91 à 120 sur 131
Discussion: Bulldozer et innovations
-
29/08/2012, 12h29 #91*X86 ADV*

- Ville
- Vence
-
29/08/2012, 15h32 #92Sorcier Hardware

tant qu'on reste en single thread oui. Il y a 4 decodeurs qui peuvent pondre 1-2 Macro-ops par cycle contre 3 sur Istanbul, MAIS ces decodeurs bossent pour deux clusters. Donc en fait il y a 4 décodeurs là ou il y en avait 2x3=6 sur Istanbul. Envoyé par newbie06

-
29/08/2012, 15h40 #93*X86 ADV*
- Ville
- Vence
OK, mais j'avais l'impression que le principal problème de BD était sa perf en single thread, qui donc ne serait pas due aux décodeurs eux-mêmes. Envoyé par Doc TB
-
01/09/2012, 17h58 #94*X86 ADV*

On ne peut pas dire que ce soit tellement la joie en multi-thread non plus. En pratique, un FX-8150 fait souvent un peu moins bien qu'un Core i7-2600K, malgré pas mal de transistors et 30 W de plus. Envoyé par newbie06
Si j'ai bien compris, les décodeurs sont actuellement partagés par entrelacement vertical, i.e. dédiés au thread 0 au cycle n, au thread 1 au cycle n+1, etc. Ça doit poser problème pour certains workloads.Mon blog (absolument pas à jour) : Teχlog
-
11/09/2012, 06h18 #95*X86 ADV*
Petite précision : les décodeurs sont complètement doublés, ça passe à 2×4-wide, et non 2×3-wide comme on aurait pu le supposer.
Mon blog (absolument pas à jour) : Teχlog
-
11/09/2012, 06h30 #96Sorcier Hardware
Sur Steamroller ? Si c'est ça, c'est qu'ils mijotent une archi à 4 clusters par core...
-
11/09/2012, 08h18 #97*X86 ADV*
Oui sur Steamroller. Je ne sais pas ce qu'ils mijotent, s'ils passaient à 4 cores par module ça serait un retour à l'état actuel, un décodeur 4-wide par paire de cores, donc il s'agit peut-être simplement d'élargir un peu chaque core. Envoyé par Doc TB
Mon blog (absolument pas à jour) : Teχlog
-
11/09/2012, 09h27 #98*X86 ADV*
Qu'est-ce qui te fait dire ça ? Envoyé par Alexko
-
11/09/2012, 10h09 #99*X86 ADV*
- Ville
- Vence
http://semiaccurate.com/forums/showp...&postcount=335 Envoyé par Foudge
")
-
11/09/2012, 15h06 #100*X86 ADV*
Merde, quand en marchant dans la rue, ayant tout à coup l'impression d'être suivi, je me retourne et crois voir une ombre disparaître subitement, en fait je ne rêve pas ? Envoyé par newbie06
Mon blog (absolument pas à jour) : Teχlog
-
11/09/2012, 15h09 #101*X86 ADV*
- Ville
- Vence
Tu veux dire que tu n'as pas encore compris qui j'étais sur S|A ? Envoyé par Alexko

-
11/09/2012, 15h12 #102*X86 ADV*
Non mais si tu changes de pseudo sur tous les forums, c'est de la triche aussi… Envoyé par newbie06
Mon blog (absolument pas à jour) : Teχlog
-
01/06/2013, 12h03 #103*X86 ADV*
Die shot d'un futur core AMD, probablement Excavator :

Dernière modification par Alexko ; 01/06/2013 à 13h32.
Mon blog (absolument pas à jour) : Teχlog
-
01/06/2013, 13h02 #104*X86 ADV*
Steamroller tu veux dire ?
-
01/06/2013, 13h31 #105*X86 ADV*
Apparemment les FPU sont doublées (deux FMA de 256 bits par cycle) ce qui n'est pas prévu pour Steamroller, en plus de changements côté integer qui n'avaient pas été mentionnés non plus. Donc soit le design de Steamroller a considérablement changé depuis son annonce (ce qui ne me paraît pas possible, compte tenu du calendrier) soit c'est Excavator.
Mon blog (absolument pas à jour) : Teχlog
-
01/06/2013, 13h56 #106*X86 ADV*
Je m'attendais pas à un dieshot d'Excavator si tôt.
Ces 2 FPU 256bit seront toujours partagées ? Si non, avec le doublement du nombre de décodeurs dans Steamroller, ça va de plus en plus ressembler à un dualcore leur module
-
01/06/2013, 14h06 #107*X86 ADV*
Apparemment, oui. La meilleure référence est probablement ce post de Fellix, qui contient une image de comparaison avec Bulldozer et Piledriver, ainsi que les analyses de Hans de Vries et 3Dilettante : http://crazyworldofchips.blogspot.fr...ot-leaked.html
Ils soupçonnent tous les deux un passage à 4 threads par module (vraisemblablement 2 threads par core).Mon blog (absolument pas à jour) : Teχlog
-
09/06/2013, 22h34 #108*X86 ADV*
Ce die shot ne semble pas tellement vous inspirer. Fefe, pas de réaction ?
Mon blog (absolument pas à jour) : Teχlog
-
09/06/2013, 22h40 #109*X86 ADV*
- Ville
- Vence
C'est franchement pas facile de tirer des infos d'un die-shot. Même sur nos designs j'ai du mal alors pour un design concurrent je vais me taire
-
10/06/2013, 02h04 #110*X86 ADV*
Hans de Vries semble y arriver assez bien. Pour moi ça tient carrément de la science occulte, mais bon… :D Envoyé par newbie06
Mon blog (absolument pas à jour) : Teχlog
-
10/06/2013, 11h20 #111*X86 ADV*
- Ville
- Vence
Il donne cette impression en effet. Mais au final a-t-on la preuve qu'il ne se trompe pas ? Envoyé par Alexko
Pour ce que j'en sais on peut parvenir a identifier certaines structures comme des RAM, on peut aussi identifier des regularites. Si on ajoute les infos donnees par les constructeurs sur les tailles de ces structures, des die-shots proprements identifies d'une generation precedente, on peut faire avancer l'identification des unites.
De la a identifier les ressources de rename et dire qu'elles ont double, ou dire que les changements a la branch pred sont massifs, je me pose des questions.
Desole, mais le doute cartesien l'emporte toujours chez moi
-
10/06/2013, 17h22 #112*X86 ADV Natif*

- Ville
- Far far away
Fefe il est deborde de boulot et reverse engineer un die shot correctement ca prend du temps
.
fefe - Dillon Y'Bon
-
18/06/2013, 14h23 #113*X86 ADV*
Quelques interprétations du die shot (mais pour moi c'est du chinois
 )
)
http://diybbs.zol.com.cn/11/11_106645.html
Et ceci :

http://semiaccurate.com/forums/showp...&postcount=957
-
16/01/2014, 22h25 #114*X86 ADV*
Bon, ben Kaveri est sorti. Bilan très résumé : + 7,5 % d'IPC en moyenne (HFR), avec quelques pointes autour de 30 % mais aussi des chutes, probablement à cause d'une latence mémoire qui augmente d'environ 30 % (!) pour des raisons qui ne sont pas franchement claires. Les fréquences chutent un peu entre 65 W et 95 W, la faute au process plutôt tuné pour la densité.
Quelques données intéressantes ici : http://www.hardware.fr/articles/913-...ale-turbo.html
Et là : http://techreport.com/review/25908/a...essor-reviewed
Côté graphique c'est mieux, mais très limité par la bande passante. De gros progrès sous OpenCL, et mieux encore pour les applications HSA, lesquelles sont actuellement au nombre de… deux. :D Au final Kaveri n'améliore pas beaucoup la situation à 95~100 W (parfois pas du tout, ou même la détériore) mais c'est mieux à 65 W et encore mieux à 45 W. On est en droit d'espérer encore un peu plus sur les portables (15 à 35 W).
Et un die shot tout pourri où on ne voit rien, pour la route :
 Mon blog (absolument pas à jour) : Teχlog
Mon blog (absolument pas à jour) : Teχlog
-
16/01/2014, 22h52 #115*X86 ADV*
- Ville
- Vence
C'est pas juste des applications OpenCL 2.0 ? En tout cas, sur le repo source de LibreOffice y'a que de l'OpenCL pour accélérer Calc. Envoyé par Alexko
-
17/01/2014, 00h09 #116*X86 ADV*
Et tout ça grâce à 85% de transistors en plus ! Envoyé par Alexko
-
17/01/2014, 00h58 #117*X86 ADV*
OpenCL 2.0 supporte l'espace mémoire virtuel unifié, donc je pense qu'il suffit d'utiliser OpenCL 2.0 pour tirer parti de HSA ; mais j'ai peut-être compris de travers. Envoyé par newbie06
L'essentiel est probablement parti dans le GPU. Envoyé par Foudge
Mon blog (absolument pas à jour) : Teχlog
-
17/01/2014, 11h02 #118*X86 ADV*

Oui. Au détail près que le support d'OpenCL 2.0 est prévu pour Q1 2015 chez AMD. (Ça reste infiniment plus tôt que celui d'OpenCL 1.2 chez Nvidia. Envoyé par Alexko
") )
)
-
18/01/2014, 23h09 #119*X86 ADV*
Ah, bah du coup je sais pas comment LibreCalc fonctionne, alors. Mais ça a l'air d'être efficace. On doit être dans ce qu'on appelle la pratique. Envoyé par Møgluglu
Sinon, vous avez une idée des causes de ça ?
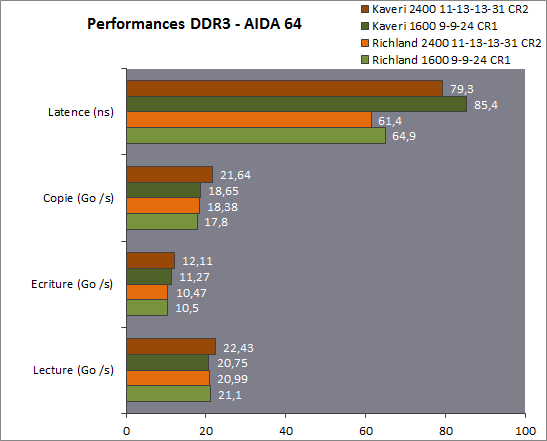
http://www.hardware.fr/articles/913-...ddr3-2400.html
Alors que pour Haswell : Envoyé par HFR
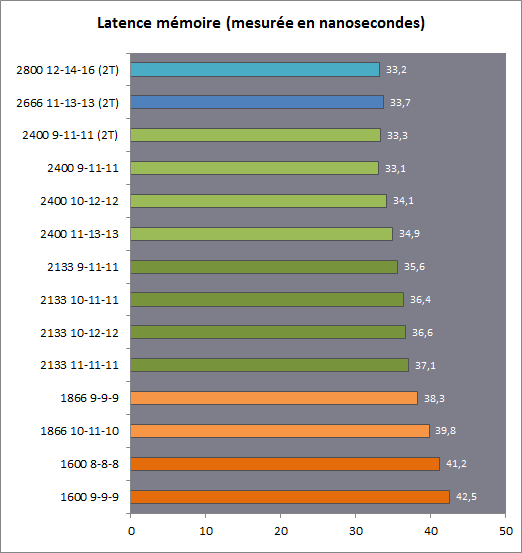
http://www.hardware.fr/articles/909-...e-memoire.html
C'était déjà pas brillant pour Richland, mais l'écart avec Haswell est devenu énorme.Mon blog (absolument pas à jour) : Teχlog
-
18/08/2016, 16h39 #120*X86 ADV*

- Ville
- Grenoble
Premières slides sur Zen (à ma connaissance)
Vu de haut ça fait un peu plus rêver que les dérivés de Bulldozer qu'on avait jusqu'ici. Au programme, SMT et uop-cache (6 uops/cycle, ce qui fait autant que chez Intel si mes souvenirs sont bons). Idem, 4 instructions par cycle au Decode, un peu réminiscent du bon vieux 4-1-1-1. Pendant la démo leur engineering sample était à 3GHz mais apparemment ils visent plus haut pour les versions finales. Rien n'est dit sur le Turbo.
Sinon les parties INT et FP sont toujours séparées même si le(s) scheduler(s) serai(en)t 1.75x plus gros que sur Excavator. Un autre point intéressant, il n'y a que 2AGU (mais 4ALU) alors que le D-Cache supporte deux loads 128-bit et un store 128-bit par cycle. A voir dans le manuel d'optimisation quand il sera sorti. Envoyé par François

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non