
T'as raté la dernière ligne de mon message, mais tu as bien raison

Affichage des résultats 241 à 270 sur 658
Discussion: Archi GPU et GPGPU
-
26/08/2009, 18h02 #241*X86 ADV*

- Ville
- Vence
-
23/09/2009, 21h33 #242*X86 ADV*

J'imagine que tout le monde a déjà lu l'article de Damien:
http://www.hardware.fr/articles/770-...n-hd-5870.html
Il répond à la question qu'on se pose quand on voit les 2 boîtes Rasterizer sur le schéma d'AMD...
La mort des interpolateurs d'attributs parait aussi une évolution logique.
Le fait de séparer les cores en deux clusters vise à simplifier l'interconnect, j'imagine. Je me demande quelle influence ça a sur le débit et la latence. Une guerre crossbars hiérarchiques vs. Ring bus qui se prépare?")
Sinon j'arrive pas à trouver la source de l'affirmation, qui m'intéresse :
...et j'ai la flemme de télécharger tout le SDK DirectX d'août 2009 juste pour en extraire la doc (qui n'est pas sur MSDN) dans l'éventualité qu'elle contienne l'info que je cherche. Personne n'aurait ça qui traine par hasard?...Evolution importante, Cypress supporte le nouveau standard IEEE754-2008 qui est requis par Direct3D 11.
-
23/09/2009, 23h28 #243*X86 ADV*
- Ville
- Caribou fondu
Demande lui directement sur l'Openbar GPU sur HFR

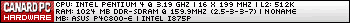
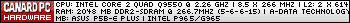
-
23/09/2009, 23h33 #244Banni
- Ville
- DTC
Il a pas confondu avec Opencl plutot?
-
24/09/2009, 09h01 #245*X86 ADV*
Y'a bière à volonté? Envoyé par Oxygen3
Envoyé par Oxygen3


Ah non, juste un topic de 900 pages.
Mais merci, bonne idée.
Je pense pas que Damien confonde OpenCL et Direct3D... Envoyé par Bncjo
")
Après, ça serait pas étonnant (et même largement souhaitable) que les deux standards aient les mêmes prérequis.
À savoir le FMA, les dénormaux et 4 modes d'arrondi statiques en double précision, et que dalle ou presque en simple.
-
25/09/2009, 11h55 #246*X86 ADV*
Quelques zolis dessins de Goto, en bas de page : Envoyé par Møgluglu
http://pc.watch.impress.co.jp/docs/c...24_317309.html
Dans l'ordre, la topologie de l'interconnect du RV770, ce qu'aurait été l'interconnect de Cypress avec la même topologie, ce qu'est (probablement) l'interconnect de Cypress.
-
26/09/2009, 01h05 #247*X86 ADV*
- Ville
- Vence
En tout cas, je suis impressionné par les résultats des 5870. Un bien beau boulot à tous les niveaux.
Ha il manque juste un détail : où sont les drivers Linux ? (Sachant que mon fondement n'abrite pas ce genre d'engins.)
-
26/09/2009, 11h33 #248*X86 ADV*
Chez AMD? Envoyé par newbie06
C'est pas officiellement supporté par les Catalyst 9.9 (ne serait-ce que parce que le release notes du driver datent d'avant la fin du NDA), mais en pratique ça semble marcher, au moins pour CAL/Brook+:
http://forums.amd.com/devforum/messa...hreadid=119351
Alors arrête de troller sur les drivers ATI ici aussi.
-
26/09/2009, 11h42 #249*X86 ADV*
- Ville
- Vence
Je ne trollais pas, je posais sérieusement la question. Je m'étais arrêté à la news de Phoronix: http://www.phoronix.com/scan.php?pag...item&px=NzU0OQ
Que cela fonctionne sans être officiel me paraît tout à fait suffisant pour le moment. J'ai vécu ça avec ma GTX 275 pour laquelle il m'a fallu utiliser un driver beta qui ne la supportait même pas officiellement. Ca marchait nickel.
-
01/10/2009, 13h37 #250*X86 ADV*
- Ville
- Liège (Belgique)
http://www.hardware.fr/articles/772-...computing.html
De la lecture

-
01/10/2009, 15h27 #251*X86 ADV*

Damien est productif en ce moment.
Edit :
3 milliards de transistors...
J'espère pour eux que TSMC sera à la hauteur de leur ambition.Dernière modification par Yasko ; 01/10/2009 à 15h37.
-
01/10/2009, 17h36 #252*X86 ADV Natif*

- Ville
- Far far away
Il me semblerait qu'il se plante d'un facteur 2 pour les int32 sur i7 (2 ports 4 wide et 4 cores).
Il y a aussi le fait que le core pourra probablement turbo de quelques points de frequence sur un workload entier, mais la je chipote surtout que la frequence de Fermi est juste approximee.
Et vu la quantite de types d'operations reportes, pourquoi ne pas aussi compter int16add, in16mul et int16 MAD ? Ce sont des types de donnees nettement plus utiles que les int32. Bien entendu le ratio entre CPU et GPU tombe de maniere significative (passe de 10x+ a 2x+), mais c'est assez interressant car ca montre ou le GPU est optimise et ou il est faible (et ses graphes actuels ne montrent pas une certaine faiblesse en entier alors que c'est le cas).
D'ailleurs si on allait plus loin et on mesurait la puissance de calcul en int32 scalar on arriverait a une comparaison interressante pour du code "classique".
Newbie06, quand est ce que tu recompiles coremark pour Fermi ?
Dernière modification par fefe ; 01/10/2009 à 17h43.
fefe - Dillon Y'Bon
-
01/10/2009, 19h40 #253*X86 ADV*
- Ville
- Vence
Quand nVidia m'aura envoyé un exemplaire *et* qu'Intel aura fait de même avec LRB. Là, je m'engage pas trop, je suis tranquille Envoyé par fefe
Sur Fermi : http://www.realworldtech.com/page.cf...WT093009110932
-
02/10/2009, 18h25 #254*X86 ADV Natif*
- Ville
- Far far away
http://www.semiaccurate.com/2009/10/...mi-boards-gtc/
Il va falloir attendre un peu pour avoir un exemplaire pas en bois
fefe - Dillon Y'Bon
-
02/10/2009, 19h07 #255Tyranaus0r

La carte brandie par Huang au GTC semblerait être un joli fake :
http://www.comptoir-hardware.com/act...ros-fake-.html
Pfffffff
-
02/10/2009, 19h13 #256*X86 ADV Natif*
- Ville
- Far far away
Qu'est ce qui est le mieux pour un departement de PR ? Laisser le/les competiteurs voler la vedette avec des annonces et demos de produits ? Ou faire un paper launch, et menacer ceux qui crient au loup ?
Option 2, ca justifie leur existence bien sur !fefe - Dillon Y'Bon
-
02/10/2009, 22h44 #257*X86 ADV*

http://www.fudzilla.com/content/view/15798/1/ Envoyé par Fudo
Même si la démo tournait sans doute sur un vrai GT300/Fermi, ils passent quand même bien pour des cons...
-
02/10/2009, 23h57 #258*X86 ADV*
Pas sûr que ça aurait du sens. Apparemment Fermi comme Tesla n'a pas d'instruction scalaire. Que du vectoriel... Envoyé par fefe
Du coup ce serait un peu malhonnête, autant que comparer le GPU contre du code OpenCL vectorisé en SSE avec 4 threads/"warp" et un système de branchements-prédication bricolé.
Envoyé par newbie06
C'est marrant, sur Tesla on avait mesuré entre 5 et 12 microsecondes...The latency for context switch between kernels has also been reduced by 10X to around 25 microseconds,
J'imagine qu'on doit pouvoir trouver au moins un protocole de test qui permette d'obtenir un gain de x10.
Pas compris.Fermi introduces full predication for all instructions to improve the instruction fetch by removing bubbles caused by taken branches. In GT200, a divergence would result in a warp executing through and then branching between each control flow path. At each branch, the warp would stall until the branch could be resolved and the next address fetched. With predication, the warp can sequentially execute through all the divergent control flow paths, without branches, and simply mask off the unused vector lanes.
Il veut dire que Fermi fait de la prédiction de branchement? Ou de la prédication à la Itanium en spéculant sur les deux branches à la fois?
Ou alors juste qu'ils ont simplifié leur usine à gaz de politique de parcours des branchements en SIMD, et que maintenant ils exécutent le code dans l'ordre comme tout le monde (AMD, Intel) au lieu de sauter dans tous les sens...
Et il a foiré sa biblio, Kanter...
Un truc qui m'étonne, c'est que NVidia n'a pas remis en cause son choix de faire du multithreading à un seul niveau. Chez AMD on a du multithreading au niveau clause et au niveau instruction, sur Larrabee on aura les threads et les fibers en soft : un niveau à grain fin pour masquer les latences du pipeline d'exécution, et un niveau à plus gros grain pour masquer les latences mémoire.
Peut-être que le choix de NVidia prend tout son sens avec le cache : les accès mémoires on une latence beaucoup moins déterministe et on ne peut plus les considérer comme des opérations longues tout le temps.
En tout cas, NVidia confirme bien son positionnement avec des GPU que ressemblent de moins en moins à des GPU (moins de threads, moins de registres donc moins de parallélisme de données, moins de latence... Et plus d'ILP?)
-
03/10/2009, 02h14 #259*X86 ADV Natif*
- Ville
- Far far away
Je ne cherchais pas a etre honnete/malhonete, just a lister quelques cas ou ca ne marchait pas si bien histoire de ne pas montrer que les points forts de la bete. Envoyé par Møgluglu
fefe - Dillon Y'Bon
-
07/10/2009, 07h55 #260*X86 ADV*
- Ville
- Vence
-
07/10/2009, 11h52 #261*X86 ADV*
Charlie est en pleine forme.

Ce qui est étonnant, c'est surtout qu'ils soient autant à la bourre sur les dérivés desktops milieu/bas de gamme du GT200, avec DX 10.1 et la GDDR5.
Depuis le "lancement" du GTS 260M en juin, plus de nouvelles des GT215 en 40nm...
Je vais finir par croire Charlie sur les yields. Envoyé par NVidia en juin
-
07/10/2009, 13h29 #262*X86 ADV*
J'avais du mal à le croire au début, mais plus ça va, plus j'ai l'impression qu'il a raison. Sur les dérivés du GT200, il incrimine le contrôleur GDDR5, entre autres.
Mine de rien si le GT300/Fermi sort avant ou presque en même temps que les dérivés du GT200, ça va faire tache...!
-
07/10/2009, 15h06 #263*X86 ADV*
- Ville
- Vence
C'est pas grave tout ça, ils vont pouvoir se concentrer sur Tegra
-
07/10/2009, 15h28 #264*X86 ADV*
- Ville
- Caribou fondu
On peut critiquer Charlie tant qu'on veut, mais son article sur les 'shortages' mentionné est très très intéressant sur le fonctionnement du channel Envoyé par newbie06
http://www.semiaccurate.com/2009/10/...5-prices-soon/
Looking at raw wafer and silicon costs, a TSMC 55nm wafer costs about $4000, and you can get about 110 G200 die candidates on one. That puts the raw silicon cost at about $35 for any GTX260/275/285 card, and if you are being generous, add only $5 for packaging and testing. That means there is at least $40 worth of silicon in the G200b based GPUs.
On the cards, there is at least another $30 worth of components like RAM and HDMI chips, so there is no way these can be sold for a profit. The chip is too big, the boards are too complex, and the performance simply isn't there. There is no way that the 260 and 275 can make money if ATI prices Juniper at $125 and $175 for the low and high end variants respectively.
-
07/10/2009, 17h00 #265*X86 ADV Natif*
- Ville
- Far far away
Articles interressants, meme si on ignore le cote scoop alarmiste.
fefe - Dillon Y'Bon
-
11/10/2009, 17h41 #266*X86 ADV*
J'avais raté ça, pourtant y'a un lien énorme sur la page d'accueil de NVidia:
http://www.nvidia.com/object/fermi_a...e.html#experts
Décidément, Patterson est tombé bien bas.
Malgré les grosses ficelles de PR (comparaison avec un G80 sorti il y a 5 ans et attribution de tous les changements incrémentaux depuis, oubli de la concurrence ou comparaisons inadaptées et FUD divers...), y'a quelques points intéressants.
Par exemple le sursaut d'honnêteté de Glaskowsky, sur le langage intermédiaire PTX, qui devait durer 20 ans il y a 4 ans :
Jetez tout et recommencez, en attendant PTX 3.0...NVIDIA intends PTX 2.0 to span multiple generations of GPU hardware and multiple GPU sizes within each generation, just as PTX 1.0 did.
En passant j'ai ma réponse pour l'histoire de prédication dans l'article de RWT. C'est juste un changement au niveau de PTX, pas au niveau du hard qui a toujours supporté la prédication.
Peut-être qu'à force de rapprocher PTX du langage assembleur natif, ils se rendront compte qu'ils pourraient aussi bien générer l'assembleur directement. Et le documenter.
-
11/10/2009, 23h03 #267*X86 ADV*
- Ville
- Vence
S'il est capable de faire ça pour un sponsor secondaire du ParLab, je me demande ce qu'il va faire pour LRB, qui est fait par un des deux sponsors majeurs. Envoyé par Møgluglu
-
12/10/2009, 12h16 #268*X86 ADV*
"I believe history will record Fermi as a significant milestone" peut être interprété de plusieurs manières.
Le fait que ce soit le dernier GPU produit par Nvidia de son vivant pourrait effectivement le faire rentrer dans l'histoire.
-
12/10/2009, 13h58 #269*X86 ADV*
2015 : publication d'un article complet sur CPC à propos de Fermi, et ce qu'il serait devenu si NVidia n'avait pas coulé en 2010, dans la tradition des rétro-reviews.
http://canardpc.com/dossier-26-retro...oo_5_6000.html
-
12/10/2009, 14h53 #270*X86 ADV*
Vous êtes méchants, Nvidia tiendra bien jusqu'en 2011...

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non