
Désolé, j'ai fait un raccourci malheureux en disant ALU et FPU. Et les latences que j'ai données sont pour 1 warp, ce qui change tout.
On a en fait :
- ALU+FP32U, latence back-to-back mesurée pour 1 warp 16 cycles + 2 cycles par registre lu
- FP64U, 54 cycles + 4 cycles par registre lu
L'ALU+FP32U n'a apparemment pas bougé depuis le G80 et est telle que décrite dans ce brevet :
Multipurpose functional unit with multiplication pipeline, addition pipeline, addition pipeline and logical test pipeline capable of performing integer multiply-add operations Ming Y. Siu et al.
Dans lequel ils écrivent :
(vive Google...)
Comme on a 8 unités comme ça, on passe 4 fois dedans en pipeline pour exécuter un warp, donc la latence du calcul serait de 13 cycles, arrondi à 14 vu que le scheduler et le banc de registre tourne à la moitié de la fréquence.
Ça ferait donc 2 cycles pour écrire la destination, et 2 cycles pour lire chaque opérande de manière non pipelinée. Ce qui correspond à 1 cycle à la fréquence du banc de registres.
À noter que cette unité ne supporte ni le FMA, ni les dénormaux, ni même les multiplications entières 32x32. NVidia à 2 arithmétiques totalement indépendantes : une simple rapide et un peu crade pour le graphisme, et une double lente et propre pour le GPGPU.
Pour les FP64, là on n'a qu'une unité, donc il faut passer 32 fois dedans. [Edit: et oui c'est là qu'on cycle plusieurs fois...]
Si on suppose que les registres doubles prennent 4 cycles à lire/écrire, il reste 19 cycles pour l'exécution, ce qui est déjà plus raisonnable.
Ton calcul c'est 500 cycles (latence lecture mémoire) / 24 (fréquence de scheduling) / 4 coût (débit) d'une opération = 5,2 arrondi à 8 lectures simultanées par thread = registres nécessaires par thread pour masquer la latence?J'etais arrive aux memes calculs de registres / thread. Si tu as une operation de reduction a faire et que tu veux la masquer il te faut 1 registre destination par cycle de latence effective (je compte 1 cycle = frequence a laquelle ce thread schedule) de l'operation de reduction. Donc avec 8 registres on ne recouvre meme pas une reduction en flottant vu qu'il faut quelques registres en plus que 8 pour stocker les sources. 16 m'a l'air suffisant par contre.
Merci.Partie centraledes SM, oui. Pour les dimensions, un peu plus haut qu'un FP24, et la largeur de 2FP24 + leurs registres). On arrive a peu pres a distinguer le bloc en passant une photo de die sous photoshop avec un bon unsharp mask. J'ai compte les pixels et compare au nombre de pixels pour le die complet (je sais c'est pas super scientifique mais bon.

Affichage des résultats 61 à 90 sur 658
Discussion: Archi GPU et GPGPU
-
29/06/2008, 18h11 #61*X86 ADV*


-
29/06/2008, 19h00 #62*X86 ADV Natif*

- Ville
- Far far away
Ok je comprends mieux, l'unite decrite dans le patent a 8 etages, ce qui est donc dans le domaine du raisonable pour le pipelining, le reste correspondant a la latence des registres et a la distance entre le scheduler et l'unite d'exec (vu qu'ils tournent a la moitie de la frequence ca fait 4 clocks pour l'acces registre plus la distance du scheduler a l'unite si ils n'ont pas de reseau de bypass - et je doute qu'ils en aient un). Envoyé par Møgluglu
Envoyé par Møgluglu

Ca me rassure avec 60 clocks je ne comprenais vraiment pas comment ils auraient pu pipeliner leurs operateurs.
J'etais parti dans l'autre sens: 32KB de register file sur le G80Ton calcul c'est 500 cycles (latence lecture mémoire) / 24 (fréquence de scheduling) / 4 coût (débit) d'une opération = 5,2 arrondi à 8 lectures simultanées par thread = registres nécessaires par thread pour masquer la latence?
24warp*32threads*4(B/registre)*nb_reg_per_thread=32KB (register file par SM)
Tu arrives a 10, que j'arrondis gentiment a 8 etant certain qu'il y a des restrictions.fefe - Dillon Y'Bon
-
30/06/2008, 13h28 #63*X86 ADV*
Pour les latences des lectures, j'obtiens ça :
Finalement ça n'a pas autant augmenté que je pensais, surtout que les résultats doivent être différents sur le GT200 final.
La latence convertie en cycles mémoire me fait dire que la majeure partie vient du contrôleur.
Quelqu'un sait s'il y a moyen de connaître les réglages des latences de la mémoire vidéo (tCL, tRAS, etc.) des cartes NVidia? GPU-Z a pas l'air de savoir. Pour les Radeon rovclock me donnait ça autrefois...
Au pire on doit pouvoir les retrouver avec la datasheet de la DRAM en connaissant la fréquence.
-
30/06/2008, 14h07 #64*X86 ADV Natif*
- Ville
- Far far away
Je n'ai les datasheet que pour les versions non 'G', mais tCL sur de la DDR3 1600 est a 8 (10ns) pour le haut des specs jedec, si tu regardes la latence d'un acces qui fait un page hit, tu taperas generalement dans les 25-30ns en comptant les IO et les pipelines du controleur memoire (probablement plus si tu as un grand nombre d'acces potentiel en parallele car tu traverses probablement plus de schedulers). Ajoute 10ns pour un page empty, et 20ns pour un page miss (C'est pour ca que j'ai choisi la DDR3-1600 les calculs sont vite faits
). Le reste de la latence vient du (C/G)PU et de ses chemins de donnees qui conduisent aux controleurs memoire.
Edit:
Si on se refere a Tom's: http://www.tomshardware.com/reviews/gddr,783-2.html
Donc si on prend de la GDDR3 a 800, les timings sont probablement similaires a la DDR3-1600 soit 8 donc 10ns pour tCL...Code:Modules Type Voltage VDD,VDDQ Frequency Range Read Latency 128M bit GDDR-1 2.5V, 2.5V 183-500 (800)MHz* 3,4,5 256M bit GDDR-1 2.5V, 2.5V 183-500 (800)MHz* 3,4,5 256M bit GDDR-2 2.5V, 1.8V 400-500 MHz 5,6,7 256M bit GDDR-3 1.8V, 1.8V 500-800 MHz 5,6,7,8,9
Edit2:
Pour ceux qui se demandent comment un CPU peut avoir 45-50ns de latence memoire avec un controleur memoire integre quand 30ns provienennt du controleur et de la memoire, je rappelle qu'un hit dans le cache de dernier niveau coute dans les ~45 cycles sur un K10 donc dans les 20ns, et Anand a mesure dans les 13-14ns sur un Nehalem (~40 clocks).
Et Latence hit L3 + Latence memory controler est generalement une bonne approximation de la latence totale (load to use, en pratique un peu optimiste).
Mais dans le cas des GPUs ou le L2 est a 20 cycles sur le G80 (~20ns), il est clair qu'il y a autre chose qui intervient que dans les CPUs. On peut supposer par exemple que les acces sont bufferises suffisament longtemps pour garantir qu'une page entiere sera quasi systematiquement chargee histoire de maximiser l'efficacite, ce qui represente 170ns mini (si on veut avoir une page de buffering, en comptant le premier acces comme page empty). Il y a probablement une 20 aine de ns ou la demande est routee globalement et envoyee au controleur. De cette maniere j'arrive a 170+30+20+20 =~250ns et je suis encore beaucoup trop court... Donc je ne vois pas d'ou vient leur latence gigantesque.Dernière modification par fefe ; 30/06/2008 à 14h31.
fefe - Dillon Y'Bon
-
30/06/2008, 15h11 #65*X86 ADV*
Je suis arrivé à peu prés à la même chose avec la datasheet de la Samsung : pour 1000-1100MHz, CL=12 et RCD = 14. Envoyé par fefe
Si on suppose que la requête est dispatchée sur 1 seul contrôleur 32-bits (?), le transfert des 1024 bits en DDR prend 16 cycles, donc au total une quarantaine de cycles à 1GHz (page empty).
[Edit: les contrôleurs sont 64-bits, donc 8 cycles de transfert, mais ça ne change pas grand-chose au total]
Il reste ~280ns pris par le GPU lui-même, soit ~160 cycles à la fréquence core.
Dans Cuda, les lectures en mémoire globale bypassent en principe tous les caches, donc ça doit venir principalement des monstrueux buffers et des unités de réordonnancement des accès...
Peut-être que les lectures stream passent quand-même par tout le pipeline de texturing : calcul d'adresse 2D, filtrage, etc.Mais dans le cas des GPUs ou le L2 est a 20 cycles sur le G80 (~20ns), il est clair qu'il y a autre chose qui intervient que dans les CPUs. On peut supposer par exemple que les acces sont bufferises suffisament longtemps pour garantir qu'une page entiere sera quasi systematiquement chargee histoire de maximiser l'efficacite, ce qui represente 170ns mini (si on veut avoir une page de buffering, en comptant le premier acces comme page empty). Il y a probablement une 20 aine de ns ou la demande est routee globalement et envoyee au controleur. De cette maniere j'arrive a 170+30+20+20 =~250ns et je suis encore beaucoup trop court... Donc je ne vois pas d'ou vient leur latence gigantesque.
Pour les buffers de la taille d'une page, je suis pas sûr que ce soit nécessaire pour une DRAM moderne. Vu qu'on a 8 banks/chip, on a le temps de charger et décharger des pages sur une bank pendant qu'on transfert sur les autres en mode burst. En principe on peut maintenir comme ça le bus occupé avec des lectures aléatoires en bursts de 4 ou 8 (après si on mélange avec des écritures ça se complique...)
Enfin c'est comme ça que ça marchait quand je m'amusais à écrire un contrôleur de SDRAM PC66 sur FPGA
D'ailleurs il me semble (à vérifier) que tant qu'on fait des requêtes 1024-bits bien alignées, on peut atteindre la BP théorique même si les accès sont tous dispersés.
Ça pourrait être intéressant de mesurer les latence des instructions de sampling de texture (avec cache + filtering) et comparer. À faire pour quand j'aurai le temps
Dernière modification par Møgluglu ; 30/06/2008 à 15h19.
-
30/06/2008, 15h55 #66*X86 ADV Natif*
- Ville
- Far far away
Bon je vais essayer de reprendre les calculs a 0 en arretant le calcul mental histoire de ne pas me perdre. Pour atteindre une tres bonne efficacite en R/W sur du traffic "CPU" il faut ~2KB de buffering par controleur memoire 64bits, soit 1 a 4 pages suivant le type de modules employe. Sur les cpus ces buffers sont des entrees d'un scheduler qui dispatch les requetes en fonction d'un algo assez complique pour amximiser bande passante et minimiser la latence. Le GPU n'a aps le 2 eme probleme donc peut employer un algorithme qui a une latence a peu pres constante mais garani qu'une fois une page ouverte un maximum d'acces y sera fait ou si ce n'est pas le cas ils auront une tres bonne visibilite du futur donc saurant si il faut fermer la page ou la garder ouverte. Envoyé par Møgluglu
2KB a 64b/clock ca fait 256 clocks, et a 1.25ns de temps de cycle ca fait 320ns pour transferer tout le buffer +10ns pour ouvrir la page soit 330ns donc en fait ca semble etre impossible, le reste de la latence etant consommee par l'acces au L2 et le routage jusqu au controleur memoire et 30 a 50ns.
Une autre possibilite est comme tu le dis que tout passe par le meme datapath que le texturing (et la je suis loin de comprendre les implications).
Pour tes acces alignes sur 1024 bits mais randomises ca depend du command rate de ton controleur memoire, tu payeras une ouverture de page a chaque acces et perdras ~15% de bande passante sur un design economique. Cote efficacite une fois une page ouverte la transferer completement est ce que tu peux faire de plus rentable.fefe - Dillon Y'Bon
-
30/06/2008, 18h47 #67*X86 ADV*
Supposons qu'un contrôleur mémoire ait 8 files de requêtes correspondant au 8 banks d'une puce de DRAM. Si mes requêtes sont randomisées la probabilité de tomber sur chaque banque va être égale et mes 8 files vont se remplir à peu près à la même vitesse.
Le contrôleur devrait pouvoir masquer la latence des ouvertures (active) et fermeture de page (precharge) en switchant d'une bank à l'autre.
Si je dessine un chrono avec l'activité de chaque bank, j'aurai par exemple :
(Read correspond à tCL, Burst est le transfert effectif)
J'ai supposé un command rate de 1T, en 2T on perd quelques cycles par requête, à moins d'activer l'auto-precharge. Mes requêtes font 16 mots, soit 2 bursts, donc je dois faire 2 read à la suite...Code:Data xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Cmd A A R R A R RPA R RPA R RPA R RPA R RPA R RPA R RPA R RPA R RA R P 0 Active----ReadRead----Burst---Precharge- Active----ReadRead----Burst---Precharge- 1 Active----ReadRead----Burst---Precharge- Active----ReadRead----Burst---Precharge- 2 Active----ReadRead----Burst---Precharge- 3 Active----ReadRead----Burst---Precharge- 4 Active----ReadRead----Burst---Precharge- 5 Active----ReadRead----Burst---Precharge- 6 Active----ReadRead----Burst---Precharge- 7 Active----ReadRead----Burst---Precharge-
Dans se cas on s'en fout de savoir si deux requêtes sont dans la même page, on paie systématiquement le prix de l'ouverture/fermeture de page en latence, mais pas en débit.
Je dis pas que c'est fait comme ça, je donne juste une possibilité.
En vrai il me semble que ce n'est pas possible car les requêtes sont plus courtes que ça.
D'ailleurs sur le G80 et GT200 maintenant que j'y pense c'est 512 bits la taille d'une requête et pas 1024, ils conseillent juste de faire les accès sur 1024 bits pour scaler sur les futures générations.
Pour un contrôleur 64-bits, ça donne des bursts de 8, soit 4 cycles DDR et ça suffit pas pour remplir le pipeline...
M'enfin du temps de la SDR en 2-2-2-3 ça pouvait marcher
-
30/06/2008, 20h02 #68*X86 ADV Natif*
- Ville
- Far far away
Oui en 1N tu peux facilement overlap, mais aux frequences auxquelles ils montent les DDR, j'ai des doutes qu'ils le tiennent. 2N beaucoup plus probable. Et tu n'as que des reads
.
fefe - Dillon Y'Bon
-
30/06/2008, 20h05 #69*X86 ADV*
Nibitor te permet d'avoir ça à partir de n'importe quel bios (donc pas besoin d'avoir physiquement la carte). Envoyé par Møgluglu
Sur ma 8800GT (G92), ça donne ça :

Maintenant est-ce que c'est fiable...
-
30/06/2008, 20h37 #70*X86 ADV*
Ça a l'air, ça colle parfaitement avec la datasheet de la Samsung poétiquement dénommée K4J52324QE-BJ11 (900MHz, CL=11). Envoyé par Foudge
Merci!
-
01/07/2008, 09h48 #71*X86 ADV Natif*
- Ville
- Far far away
Excellent. Je viens de jeter un oeil aux docs Hynix et a 900Mhz ils disent 11 ou 12 donc 13ns... (tout aussi poetiquement nommee HYB18H512321BF
Hier soir je me demandais si une des raisons pour les latences si elevees pouvait etre qu'il y a tellement d'unites qui peuvent acceder la memoire a un moment donne que pour atteindre une efficacite raisonable ils sont forces d'accumuler suffisament de requetes appartenant au meme stream. Quelle est la granularite typique d'un acces memoire (la taille de la ligne de cache L2) ? Mais au final en reprenant ton exemple cis-dessus on n'arrive tout de meme pas a des latences importantes.
Dans ton exemple cis dessus tu n'as effectivement besoin que de buffer 8x512bpour maintenir l'efficacite maximum en lecture (meme en 2N), pareil pour les ecritures. Si on prend un ratio 2 lectures/ 1 ecriture (classique sur CPU, aucune idee sur GPU), en attendant que le GPU accumule 24 requetes on est a peu pres garanti d'utiliser le controleur a haute efficacite. La ou je m'etais completement plante plus haut est que le temps que ca prend pour le GPU de remplir ces N requetes bufferisees n'a rien a voir avec le debit de la memoire, mais est dependant de ses chemins de donnees internes qui sont probablement nettement plus rapide (probablement 1 requete / clock). Donc meme si on attend d'avoir beaucoup de requetes en parallele, cela ne prendra pas vraiment plus de 1 cycle par requete a accumuler, peut etre 2 pour les ecritures (en considerant des acces sur 512b, ils n'ont pas de raison d'avoir des chemins de donnees interne menant au controleur qui soient si larges).
Donc au final, on a 13ns pour l'acces a la GDDR (GDDR3-1800) une 30aine? de ns pour buffer/scheduler une 20aine de ns dans les IO et le retour de donnees vers les caches, une 20aine de ns d'acces au cache L2 => 80-90ns... Ou sont les 250ns restant ?Dernière modification par fefe ; 01/07/2008 à 10h19.
fefe - Dillon Y'Bon
-
01/07/2008, 17h21 #72*X86 ADV*
Je viens de refaire les tests plus sérieusement et... les 315ns que j'obtenais sont dans le meilleur cas ou la page est déjà ouverte (j'avais oublié que j'itérais plusieurs fois sur mon code pour chauffer les caches...)
Sur la 9800GX2, je suis plutôt à 590ns sur un vrai accès random
Je fais tourner une boucle vide sur ~10000 itérations avant ma requête mémoire dans l'espoir de laisser le temps aux buffers de se flusher. Les 590ns correspondent à 2 requêtes contiguës, mais si j'en lance qu'une c'est le même temps + 8 cycles
J'ai essayé de lancer d'autres lectures dans les autres warps à des adresses successives pour voir si le contrôleur attend d'avoir assez de requêtes sur la même page pour les lancer toutes d'un coup.
Apparemment non, la première lecture me prend le même temps (à 5ns près), et j'ai les résultats suivants à intervalles moyen de 10ns. C'est beaucoup (débit de seulement 12 Go/s), mais c'est probablement parce que tous mes threads tournent sur le même SM et il y a un goulot d'étranglement à ce niveau.
Il faudrait essayer avec tous pleins de threads, différents strides, du random, etc.
Un truc marrant à faire serait d'utiliser NiBiTor pour mettre une valeur énorme à tRCD pour pouvoir compter les page miss.
Bref, j'ai trouvé de quoi m'occuper pour cet été
Au moins dans Cuda, la granularité des accès est clairement 512-bits quand on bypasse le cache. Mais c'est peut-être différent pour le cache de texture.
Pour le ratio lectures-écritures, j'imagine qu'il est supérieur en rendering où tu lis des sommets, fais plein de multitexturing avec filtrage et mipmaps avec des caches ridicules, lis dans le z-buffer, pour au final n'écrire qu'un seul pixel (en gros).
-
01/07/2008, 17h34 #73*X86 ADV Natif*
- Ville
- Far far away
Je ne vois pas ce qui peut causer dans de difference de latence, Un page miss n'est pas suppose consommer beaucoup plus que 27ns de plus. Ca veut peut etre dire qu'ils attendent effectivement d'avoir un groupe de requetes avant de les lancer et qu'ils les envoient apres un timeout si rien ne vient ? En fait c'est tellement long que je suis totalement perdu la Envoyé par Møgluglu
. A vue de nez il doit etre possible de mettre a peut pres n'importe quoi comme tCL sans vraiment impacter la perf (dans les limites du raisonable mais 10 ou 20ns de plus passeront inapercues). Ce qui est certain c'est que vu les latences tolerees leur design de controleur memoire peut etre optimise a fond pour le power et la surface, et peu importe le timing .
Uniquement si tu peux tout faire en une passe non ? Le GPU n'a pas assez de cache pour contenir une frame complete non ? Pour les acces 512 bits, c'est considere generalement comme une bonne taille de ligne de cache pour les CPUS.Au moins dans Cuda, la granularité des accès est clairement 512-bits quand on bypasse le cache. Mais c'est peut-être différent pour le cache de texture.
Pour le ratio lectures-écritures, j'imagine qu'il est supérieur en rendering où tu lis des sommets, fais plein de multitexturing avec filtrage et mipmaps avec des caches ridicules, lis dans le z-buffer, pour au final n'écrire qu'un seul pixel (en gros).
Sinon en general une latence memoire loaded inferieure a une latence unloaded (modulo le cout d'un page empty/page miss) est le signe de presence de prefetchers... Ils ont tellement de bande passante que forcement ils peuvent se permettre d'en depenser en prefetchers mais ca aussi me surprend.Dernière modification par fefe ; 01/07/2008 à 18h11.
fefe - Dillon Y'Bon
-
02/07/2008, 08h55 #74*X86 ADV*
- Ville
- Caribou fondu
Remarque débile, mais ca tapperait pas dans la mémoire centrale via du PCI-Ex ?
-
02/07/2008, 10h38 #75*X86 ADV*
Oui et non. Le multi passe n'est plus utilisé pour faire des opérations simples de combinaison entre 2 textures. Chaque passe peut nécessiter des accés massif à des textures des buffers de constantes etc. Ceci dit chaque passe peut également écrire dans N buffers 128bits (1 <= N <= 8) mais je dirais effectivement qu'aujourd'hui en graphique il y a en moyenne bien plus de lecture que d'écriture. Par exemple le simple filtrage d'une shadow map par Percentage Closer Filtering (PCF) nécessite pour les pixels de bords X accés textures 16 ou 24 bits (pour 3D mark 2006 X=64) pour une seule écriture dans le buffer résultat. Envoyé par fefe
Effectivement. Un simple color buffer non compressé 32bits 1024x1024 multi-sampler 4x demande déjà 16MB. Envoyé par fefe
-
02/07/2008, 12h18 #76*X86 ADV*
Quand on voit la surface occupée par la gestion de la mémoire (et pas des caches!) sur le die, c'est pas si absurde. Envoyé par fefe
En comptant 70 Go/s sur la 9800GX2, en 590ns on a au maxi 41Ko de données en vol. C'est peut-être énorme pour des buffers, mais par rapport à un cache c'est rien...
N'empêche que c'est là qu'on voit la vraie différence entre CPU et GPU, et qu'il suffit pas de rajouter plein de SSE/AVX à un CPU pour avoir la même chose...
Oui, il y a le rendu multipasse, mais quand le monopasse ne suffit pas c'est qu'on a plus de travail (et de lectures) à faire et au final le ratio reste à peu près le même, je pense.Uniquement si tu peux tout faire en une passe non ? Le GPU n'a pas assez de cache pour contenir une frame complete non ? Pour les acces 512 bits, c'est considere generalement comme une bonne taille de ligne de cache pour les CPUS.
Le GPU écrit dans le framebuffer (off-chip) au fur et à mesure de la rasterization en passant par les ROP. Donc oui le contrôleur va se retrouver avec des reads et des writes en même temps. Mais vu les latence tolérées, pour les reads et d'autant plus pour les writes, il peut faire passer alternativement des trains de read et write.
Dans mon cas je lisais la même adresse exactement plusieurs fois.Sinon en general une latence memoire loaded inferieure a une latence unloaded (modulo le cout d'un page empty/page miss) est le signe de presence de prefetchers... Ils ont tellement de bande passante que forcement ils peuvent se permettre d'en depenser en prefetchers mais ca aussi me surprend.
Mais même en accès séquentiels dépendants avec stride de 128 à 1024 octets (1 à 8 requêtes), j'ai le même résultat de 315ns.
Quand je passe à un stride entre 2Ko et 32Ko :
- si je viens d'initialiser les données avant de lancer le shader -> 350ns
- sans les initialiser, ou en les initialisant longtemps avant et en faisant des mouvement mémoire entre temps -> 500ns
Du coup je vois une nouvelle hypothèses : ces GPU modernes, ça a de la mémoire virtuelle, donc des TLB... Si j'ai un TLB miss dans le dernier niveau, je dois faire 2 lectures mémoires dépendantes au lieu d'une, donc un passage de 315--350ns à 500--590ns.
Un page miss (ou TLB1 miss?) me coûterait 350-315 = 35ns, un TLB miss 150ns, et je sais pas quoi 90ns?
Pas débile du tout la remarque, mais là les données ne passent même pas par le CPU, elles sont initialisées directement en mémoire GPU (cuMemset de Cuda). Envoyé par Oxygen3
-
02/07/2008, 13h37 #77*X86 ADV*
Ou qu'on ne peut pas faire autrement (transparence, deffered shading), ou que c'est plus pratique (une passe par lumière qui utilise le même shader au lieu de N shaders qui gèrent X lumière) etc. Envoyé par Møgluglu
-
02/07/2008, 14h13 #78*X86 ADV Natif*
- Ville
- Far far away
Tout a fait d'accord, il n'y a pas que les unites d'execution, et leur modele d'exec qui sont differents mais toute la plateforme, et il est clair que cette derniere est complexe et evoluee. Rien que le fait que leur archi soit scalable entre gammes de produits pointe vers le fait que leur platforme (Tout ce qui est interconnexion, hyerarchie memoire et IO) est complexe et avancee. Envoyé par Møgluglu
Pour le ratio Read/Write je n'ai pas trouve beaucoup d'infos. Je suis tombe sur des 1/8 a 1/32 pour le ratio calcul/load ce qui est tres superieur a ce qui se trouve dans les CPUs (plus proches de 1:1 a 1:4), mais de ce que Alice et toi dites le ratio est tres nettement superieur a 2/1, donc si on veut envoyer les writes en batch ca force a bufferiser beaucoup d'acces.Oui, il y a le rendu multipasse, mais quand le monopasse ne suffit pas c'est qu'on a plus de travail (et de lectures) à faire et au final le ratio reste à peu près le même, je pense.
Le GPU écrit dans le framebuffer (off-chip) au fur et à mesure de la rasterization en passant par les ROP. Donc oui le contrôleur va se retrouver avec des reads et des writes en même temps. Mais vu les latence tolérées, pour les reads et d'autant plus pour les writes, il peut faire passer alternativement des trains de read et write.
Sinon je pars du principe que les controleurs memoires sont completement independants donc que leur buffering est local (c'est pour ca que je faisais tous les calculs precedement juste pour un controleur). Leur nombre ne devrait pas changer la latence de maniere significative, car une fois que l'adresse est hashee et envoyee vers le bon controleur il n'y a pas de differences significatives de latence qu'on est 1 ou 10 controleurs.
Bien entendu le reseau d'interconnexion pour arriver au-dit controleur sera plus complexe et probablement plus lent si il y a bcp de controleurs et si la source de l'operation memoire est particulierement lointaine sur le die.
Je ne savais pas pour la memoire virtuelle, mais effectivement ton hypothese des TLB semble tout a fait raisonable au vu des resultats de ton experience.Dans mon cas je lisais la même adresse exactement plusieurs fois.
Mais même en accès séquentiels dépendants avec stride de 128 à 1024 octets (1 à 8 requêtes), j'ai le même résultat de 315ns.
Quand je passe à un stride entre 2Ko et 32Ko :
- si je viens d'initialiser les données avant de lancer le shader -> 350ns
- sans les initialiser, ou en les initialisant longtemps avant et en faisant des mouvement mémoire entre temps -> 500ns
Du coup je vois une nouvelle hypothèses : ces GPU modernes, ça a de la mémoire virtuelle, donc des TLB... Si j'ai un TLB miss dans le dernier niveau, je dois faire 2 lectures mémoires dépendantes au lieu d'une, donc un passage de 315--350ns à 500--590ns.
Un page miss (ou TLB1 miss?) me coûterait 350-315 = 35ns, un TLB miss 150ns, et je sais pas quoi 90ns?
La difference entre 315 et 350 semble assez difficile a expliquer a moins d'avoir une TLB qui contienne tres peu d'entrees et que tu accedes a suffisament de pages pour la flusher. Les PTE evictes de TLB sont generalement caches dans la hierarchie memoire sur les CPUs, donc si on suppose que c'est le cas, tu payes un acces supplementaire au L2 si ta page etait presente precedement dans ta TLB mais a ete evictee. Tes 35ns sont dans le meme ordre de grandeur que la latence du L2 donc ca me semble raisonable.
Si la traduction n'a jamais ete chargee, alors tu dois aller la chercher en memoire et tu payes 180-250ns de plus ce qui semble raisonable aussi au vu des latences memoires mesurees meme si une grande partie n'est pas expliquee (la latence serait plus courte car il n' y a aucun interet a bufferiser beaucoup d'acces pour les grouper avec la demande de traduction de page, ils le savent et peuvent l'indiquer au controleur memoire).
Il devrait etre assez simple de verifier cette supposition en testant pour la taille de la TLB en cyclant sur 1, 2 ,4 ,... pages pour trouver a quel point la latence passe de 315 a 350 ns.fefe - Dillon Y'Bon
-
05/07/2008, 12h31 #79*X86 ADV*
Assez simple, on voit que c'est pas toi qui doit programmer dans un assembleur non-documenté sans debugger et sans IO avec ta machine qui freeze pendant 30s quand tu fais une boucle infinie Envoyé par fefe
Enfin en supposant une taille de page de 2Ko, quand je cycle sur :
- entre 1 et 32 pages -> 315ns
- entre 64 et 4096 pages -> 350ns
- entre 8192 et 65536 pages -> 500ns
Donc je pourrais avoir quelque chose comme 2 niveaux de TLB :
TLB1, 32 entrées, latence ?
TLB2, 4096 entrées, latence 35ns
(associativités à déterminer)
DRAM, latence 150ns
La latence du deuxième niveau de TLB pourrait s'expliquer si elle est partagée entre plusieurs Texture Processors.
Il n'est pas évident que les entrées évictées des TLB soient cachées. Les caches de texture sont des trucs très spécifiques dans leur mode d'adressage, avec en plus beaucoup de mouvements et de prefetching, donc les PTE risquent de se faire évicter du cache très rapidement.
Autre truc marrant, si je fais assez de mouvements mémoire avant de lancer mon shader, le tout premier accès me coûte 710ns. Je n'ai pas réussi à provoquer la même chose sur un autre accès dans le même shader, même avec un stride de 64Mo.
Mais je suis sûr qu'avec encore quelques efforts on peut arriver à la microseconde
Ou bien alors ça voudrait dire qu'on aurait les 2 niveaux de TLB, que les PTE seraient cachées, qu'un hit dans le cache coûterait 150ns et un miss 150+210ns, mais ça ferait vraiment trop monstrueux comme latences.
Ou alors un trap qui se déclenche quand on accède à une zone mémoire pour la première fois et qui met à jour la table des pages?
-
05/07/2008, 14h41 #80*X86 ADV Natif*
- Ville
- Far far away
Okok, mais conceptuellement c'est simple Envoyé par Møgluglu
, et puis tu as reussi.
4096 entrees ca fait beaucoup... Tu es sur du 2k ? Je suis tellement habitue a 4k queEnfin en supposant une taille de page de 2Ko, quand je cycle sur :
- entre 1 et 32 pages -> 315ns
- entre 64 et 4096 pages -> 350ns
- entre 8192 et 65536 pages -> 500ns") .
.
Si c'est effectivement trop complique de les cacher c'est le plus plausible. Mais rien ne les empeche de bricoler un peu la politique de remplacement pour eviter d'evict trop vite les PTE.Donc je pourrais avoir quelque chose comme 2 niveaux de TLB :
TLB1, 32 entrées, latence ?
TLB2, 4096 entrées, latence 35ns
(associativités à déterminer)
DRAM, latence 150ns
Une TLB "Locale" de niveau 1 et une TLB "globale" de niveau 2 avec beaucoup d'entrees oui. La le surcout n'est plus trop important effectivement.La latence du deuxième niveau de TLB pourrait s'expliquer si elle est partagée entre plusieurs Texture Processors.
Il te coute probablement plus cher de remplacer une page actuelle que de partir avec des entrees invalides, ou alors ils ont des cas d'aliasing detectes tardivement.Autre truc marrant, si je fais assez de mouvements mémoire avant de lancer mon shader, le tout premier accès me coûte 710ns. Je n'ai pas réussi à provoquer la même chose sur un autre accès dans le même shader, même avec un stride de 64Mo.
Mais je suis sûr qu'avec encore quelques efforts on peut arriver à la microseconde
fefe - Dillon Y'Bon
-
15/07/2008, 15h21 #81*X86 ADV*
Pour les latences mémoires, le GT200 met tout le monde d'accord

(Les observateurs attentifs remarqueront quand-même une augmentation de 5ns entre les pas de 512 et 1K. Sur le G92 c'est entre 256 et 512, et ça semble bien correspondre au nombre de contrôleurs mémoire * taille d'une requête.)
Sinon Fefe tu dois avoir raison sur les pages de 4K sur le G92. Apparemment ça serait une situation d'aliasing à 16Mo, plutôt qu'un TLB2...Dernière modification par Møgluglu ; 15/07/2008 à 15h59.
-
15/07/2008, 16h10 #82*X86 ADV Natif*
- Ville
- Far far away
C'est bien plat tout ca
fefe - Dillon Y'Bon
-
17/07/2008, 19h46 #83*X86 ADV*

Bon, messieurs les experts, j'ai quelques questions pour vous sur le RV770.
Damien nous dit ceci :
Ce que j'en conclus, c'est qu'AMD a conçu son bus mémoire et compagnie pour 6 multiprocesseurs, mais en a finalement mis 10 sans avoir à rien élargir. Envoyé par Damien
Or :
Donc chaque MP a son propre scheduler, mais j'imagine qu'il doit y en avoir un en amont qui dispatch. Envoyé par Damien
Donc la première question qui me vient à l'esprit, c'est : comment cette première étape de dispatch peut-elle être effectuée pour 10 MP par du hardware prévu pour 6 ? en admettant bien sûr qu'il y ait eu quelques modifications, mais pour une taille à peu près constante. La deuxième, c'est : les MP sont-ils vraiment bien exploités ?
Ensuite, en regardant le die, on voit très facilement les 10 multiprocesseurs :
http://img230.imageshack.us/my.php?image=diecq2.jpg
Si on se fie à cette image, on a un peu plus d'indications :
http://img241.imageshack.us/my.php?i...legendsby9.jpg
OK donc cores en rose, TMU en bordeaux, bus mémoire en vert, PCI-E en bleu, UVD en jaune, et en orange c'est quoi au juste ? J'imagine que c'est la partie qui s'occupe du dispatch et compagnie, mais on note que la zone orange est en fait composée de blocs de même taille. Que sont ces blocs ?
Si je me pose toutes ces questions, c'est en partie par curiosité, mais aussi parce que je me demande comment varierait la taille du die en fonction du nombre de MP, par exemple pour les RV730 et RV710 ou le futur RV870.
-
17/07/2008, 23h42 #84*X86 ADV*
- Ville
- Caribou fondu
Je comprends pas en quoi tu conclus que le bus a été figé AVANT le nombre de multiproc ... Envoyé par Alexko
Les blocs se designent en amont, et rien n'empeche une fois cette partie designée très tot de faire le X10 et de brancher après la partie mémoire...
-
18/07/2008, 00h42 #85*X86 ADV*
Hum oui j'ai peut-être mal interprété ce que j'ai cité... C'est vrai que ce que tu dis paraît plus logique, enfin bon, il est tard, j'y réfléchirai un peu plus demain :D
Cela dit, mes questions sur la nature de la "zone orange" tiennent toujours.
-
18/07/2008, 12h06 #86*X86 ADV*
Oui. Je ne connais pas en détail les archis d'AMD, mais chez NV l'argorithme de dispatch des threads entre les MP est ultra-simple : on découpe l'image de destination en blocs de 16x16 pixels, on les indexe séquentiellement, et quand on a n MP on affecte les blocs (k * n + i) au MP i : Envoyé par Alexko
http://www.icare3d.org/GPU/CN08
Comme c'est un algo trop balèze, ils ont soumis un brevet dessus
Du coup ce n'est pas trop dur de faire du hardware à peu près générique pour n MP.
(ou au moins de pas avoir à refaire la conception et validation à chaque GPU)
Chez NVidia non pas forcémentLa deuxième, c'est : les MP sont-ils vraiment bien exploités ?
Même si en pratique sur des cas pas trop tordus ça marche plutôt bien.
Mais peut-être qu'AMD font mieux avec leur "Ultra-threaded Dispatch Processor".
Tout le restehttp://img241.imageshack.us/my.php?i...legendsby9.jpg
OK donc cores en rose, TMU en bordeaux, bus mémoire en vert, PCI-E en bleu, UVD en jaune, et en orange c'est quoi au juste ? J'imagine que c'est la partie qui s'occupe du dispatch et compagnie, mais on note que la zone orange est en fait composée de blocs de même taille. Que sont ces blocs ?
Et en particulier les ROP et caches de texture qui s'intercalent entre les TMU et l'interface mémoire :
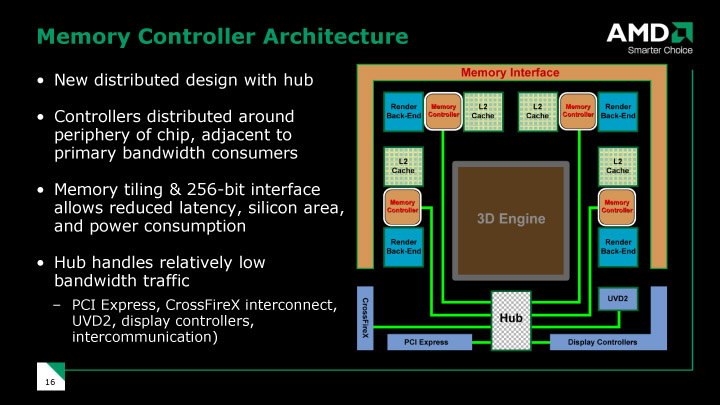
Ou en plus détaillé.
Ce qu'on observe c'est que la surface dépend aussi beaucoup du nombre de ROP=largeur du bus mémoire et d'unité de texturing. Je n'ai pas mesuré mais la surface ROP+TMU a l'air largement supérieure à la surface MP sur le GT200 et comparable sur le RV770.Si je me pose toutes ces questions, c'est en partie par curiosité, mais aussi parce que je me demande comment varierait la taille du die en fonction du nombre de MP, par exemple pour les RV730 et RV710 ou le futur RV870.
-
20/07/2008, 18h35 #87*X86 ADV*
OK, merci pour ces précisions. Dois-je en déduire que sur le RV730 par exemple, même si le nombre de MP diminue, tant que le bus mémoire reste à 256 bits on aura autant de ROPs et de contrôleurs mémoire, donc finalement une puce relativement grosse ?
-
21/07/2008, 11h42 #88*X86 ADV*
S'ils étaient déjà pad-limited avec <10 MP, ça me parait difficile de garder le même bus 256-bit pour 4 MP seulement... Même s'ils doivent pouvoir gagner de la place avec une interface GDDR3-only et moins de pads d'alim, le problème ne devrait que s'amplifier avec la diminution des finesses de gravure. Envoyé par Alexko
D'un autre côté 4 MP et bus 256-bit en 55nm, c'est exactement la config du RV670. Donc la transition se ramènerait juste à remplacer les FPU par les plus efficaces (en surface/power) du RV770 et le ring bus par un crossbar?
-
21/07/2008, 14h32 #89*X86 ADV*
Pad-limited ?
-
21/07/2008, 15h00 #90*X86 ADV*
C'est comme ça que j'interprète la phrase : Envoyé par Alexko
On peut se demander si le facteur limitant est l'arrangement des blocs ROP/contrôleurs mémoire ou bien juste les pads d'IO analogiques (tout le bord du die). La formulation de Damien semble indiquer la seconde possibilité. Envoyé par Damien
Celle de The Tech Report est un peu plus vague, mais je l'interprète pareil :
Sachant que la partie analogique scale très mal avec la finesse de gravure, et que des IO aux 3,6 GHz de la GDDR5 doivent nécessiter plus de surface que pour du 2 GHz, ça me parait vraisemblable... Envoyé par Scott Wasson

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non