
Y'a trop de nouvelles archis qui sortent.
Dans 10 ans, les gens nous regarderont en se moquant de nous, vu que pas plus d'une seule aura probablement survécu.
L'Amiga, bien sûr

Affichage des résultats 61 à 78 sur 78
-
28/04/2016, 22h37 #61:tournevis:


- Ville
- Blue team!
-
28/04/2016, 23h04 #62*X86 ADV*

- Ville
- Laincanard
Je n'ai plus d'espoir pour ce monde de brutes depuis fort longtemps. Tant qu'il existera du Little Endian en ce monde, il n'y aura aucun espoir.

-
29/04/2016, 11h29 #63*X86 ADV*

Dans les années 90, il y avait une cinquantaine de startups qui
faisaientlevaient des fonds pour faire des cartes d'accélération 3D. Et aujourd'hui il en reste encore au moins 2. (En plus de l'Atari, bien sûr.)
On est dans la même situation aujourd'hui avec les accélérateurs neuroréseautiques : on a déjà des bibliothèques qui permettent de programmer en haut niveau comme Caffe ou TensorFlow (comme OpenGL ou Direct3D), et pour lesquelles le fabriquant d'accélérateur doit juste écrire un back-end pour son architecture.
Le coût d'entrée pour le programmeur est très faible : idéalement tu branches, tu installes le driver et ça marche, comme une ATI Rage Pro 128 euh... non j'ai rien dit. En tout cas pas besoin de réécrire son code pour le porter sur la nouvelle archi.
Sinon faut arrêter avec l'antigermanisme primaire, c'est très bien le little endian. Cette atrocité de big endian, c'est juste parce que les Européens ont pas capté dans quel sens ça s'écrivait quand ils ont piqué leur système de numération aux Arabes.
-
29/04/2016, 11h35 #64*X86 ADV*
- Ville
- Laincanard
Et on dit que les x86 c'est du sérieux Envoyé par Møgluglu
Envoyé par Møgluglu

-
29/04/2016, 12h56 #65:tournevis:
- Ville
- Blue team!
Pire achat toujours Envoyé par Møgluglu

-
30/04/2016, 12h07 #66*X86 ADV*
- Ville
- Vence
J'ai pas souvenir avoir eu des soucis particuliers avec, que ce soit sous Linux ou Windows. Mais elle ne faisait que de la 2D, pour le reste, elle avait une Voodoo branchee au cul Envoyé par vectra
")
EDIT: a bien reflechir c'etait plutot une Rage Pro.
-
30/04/2016, 12h40 #67*X86 ADV*
C'est vrai, les drivers de la Rage Pro ils marchaient pas si mal.
Avec la toute dernière version beta définitive, on pouvait même faire tourner Half-Life en OpenGL :

avec des textures :

avec les bonnes textures à l'endianness près :

Et bien sûr, la 2D avec sa gestion native de l'entrelacement vertical :


-
30/04/2016, 12h48 #68*X86 ADV*
- Ville
- Vence
Comme je disais la 3D cette pov carte ne l'a jamais vue. En revanche, jamais de probleme en 2D. Pas comme les soucis en 2D avec une Fire Pro que j'ai du faire remplacer par une NVIDIA. ATI cetromoche
-
08/05/2016, 16h07 #69*X86 ADV*

Je crois que même dans un texte en arabe, les nombres sont généralement en big-endian. C'est logique vu que les Arabes ont piqué leur système de numération aux Indiens, qui écrivent de gauche à droite. Envoyé par Møgluglu
Mon blog (absolument pas à jour) : Teχlog
-
10/05/2016, 18h29 #70:tournevis:
- Ville
- Blue team!
CUDA: on remballe tout?
http://www.hardware.fr/news/13472/de...-phi-2015.html
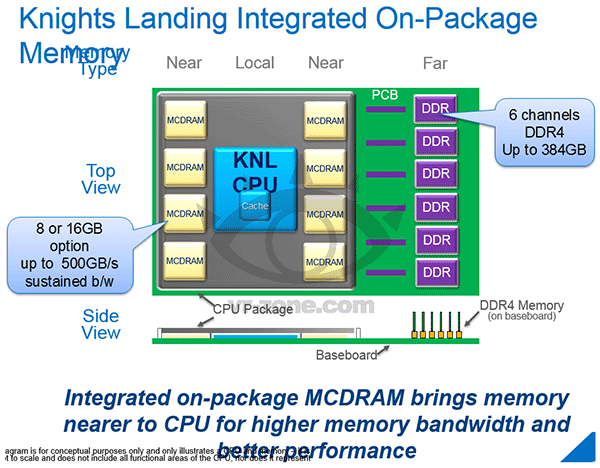
Mogluglu en avait parlé, mais j'avais pas bien capté sur le moment. Le successeur du Xeon Phi actuel, qui est un coprocesseur au même titre qu'un GPU, sera un CPU tout court. Il disposera ainsi d'un accès direct à la mémoire central par le bus DDR, certes merdique, mais beaucoup moins que le PCI express. Et surtout, il y aura de la grosse mémoire embarquée on-chip: je ne sais pas de quelle techno il s'agit, mais c'est du 500 Go/s, soit l'équivalent en BP d'un très bon GPU.
En gros, ça ferait comme que si c'était un GPU, mais qu'en fait il serait dans le CPU, et qu'il se programmerio en AVX
C'est loin d'être con sur le principe. Loin d'être gratuit non plus j'imagine.
En tous cas, je préfère voir un vrai GPU dans mon CPU plutôt qu'un FPGA. Faudrait pas non plus que je me forme en FPGA, nanmého
-
10/05/2016, 20h52 #71*X86 ADV*
- Ville
- Laincanard
Ta news date de 2013 non ?

-
10/05/2016, 20h54 #72:tournevis:
- Ville
- Blue team!
C'est pas encore sorti, mais toujours d'actualité je crois.
Si ça sort, on peut rentrer chez mémé par contre
Edit: la mémoire embarquée à 500 Go/s, c'est de la HMC, soit encore une mémoire 3-D développée conjointement entre Micron et Intel.
Mogluglu en avait parlé sur le topic des mémoires.Dernière modification par vectra ; 10/05/2016 à 21h09.
-
11/05/2016, 07h15 #73*X86 ADV*
- Ville
- Vence
La precedente generation de Phi n'a pas fait disparaitre CUDA. Y'a pas de magie : ce n'est pas parce que c'est de l'AVX et du x86 que soudainement ca devient facile d'obtenir du code tres rapide et tirant bien partie du materiel a disposition. Envoyé par vectra
Mais si tu veux tu preux prec-commander une workstation a base de Xeon Phi : http://dap.xeonphi.com/index.html. $5000 c'est tres raisonnable.
-
11/05/2016, 10h05 #74:tournevis:
- Ville
- Blue team!
Comment ils font pour faire des sites toujours plus abominables

On dirait que c'est hébergé par 1&1
5000 $ c'est vraiment pas cher pour une station complète, mes abrutis de chefs ont payé deux stations à plus de 6000 boules avec des bi-xéons à faible fréquence qui font tourner de l'excel et qui se font doser en mono-thread (voire même à 3, 4 threads). Avec les Tesla + Quadra qu'ils ont ajouté sans savoir s'en servir, je crois que les factures étaient au final entre 8 et 11k, même.
Je les appelle "victimes de la mode", mais je sais pas si ça a un rapport avec le fait qu'ils veulent me virer
Troll à part, leur mémoire 3-D sur processeur, si c'est pas mille fois trop compliqué à programmer, ça résoud énormément de problèmes pour le traitement de gros volumes de données.
De ce point de vue spécifique, c'est quand-même très bien pensé. Les données acquises arrivent forcément par les lignes PCIe vers la mémoire centrale. Elles sont lues depuis le contrôleur mémoire vers le CPU et traitées "sur place" dans leur gros cache très rapide. On peut ensuite les écrire en mémoire, voire, s'ils y pensent, les afficher directement à partir de leur mémoire 3-D vu qu'il y a normalement un contrôleur graphique embarqué sur le CPU (avec CUDA, si t'as une sortie graphique, tu peux copier de la mémoire de calcul vers la "mémoire vidéo").
Avec du 6-channel, je pense que c'est pas impossible d'espérer du 50 Go/s exploitable via le bus mémoire DDR4. Si le PCIe pouvait en dire autant...
Par contre, j'en déduis que tout est spécifique comme matériel, à commencer par la carte-mère qui doit être d'un socket spécifique. C'est bien dommage pour un usage plus "léger", vu que c'est quand-même pratique de pouvoir insérer une carte/un CPU de calcul pour booster un PC lambda.Dernière modification par vectra ; 11/05/2016 à 10h27.
-
11/05/2016, 10h26 #75*X86 ADV*
- Ville
- Laincanard
Vas-y là, tu dénigres le PCI-Express là ? Vas-y, tu veux te battre ? Envoyé par vectra

Eh ouais. GPUs forever. CUDA forever. Envoyé par vectra
")
-
11/05/2016, 10h28 #76:tournevis:
- Ville
- Blue team!
Bah chez moi, j'ai une Tesla domestiquée qui cohabite avec une GTX 660 sur une alim 430W.
Je pense pas qu'elle parte d'ici avant un moment...Dernière modification par vectra ; 19/05/2016 à 18h31.
-
19/05/2016, 18h30 #77:tournevis:
- Ville
- Blue team!
Sinon, c'est bien ici qu'on peut poster du code CUDA, ou tu préfères qu'on ouvre un autre topic?
-
19/05/2016, 18h37 #78*X86 ADV*
- Ville
- Laincanard
Ça me va très bien si c'est ici ?

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non