
Hello. Je voudrais faciliter la vie de mes collègues au boulot (je ne bosse absolument pas dans l'info) avec mes (modestes) connaissances en prog. Pour faire court et sans citer personne, on bosse avec un tiers qui nous balance tous les mois un catalogue PDF de plus de 3000 pages dans lequel on doit chercher des correspondances. On se démerde avec ctrl+F mais sur un PDF de cette taille, les recherches prennent pas mal de temps sans compter que le truc qu'on veut correspond toujours à la cinquantième occurrence trouvée, bref, c'est une perte de temps infini, qui plus est la plupart du temps devant le client... Du lourdingue de qualité.
Le PDF en question se compose d'une sorte de gigantesque tableau d'une demi-douzaine de colonne. Mon idée serait un truc qui prend des machins en entrée afin d'isoler et afficher sur une seule page un nombre restreint de lignes (en opposition au ctrl+F qui ne fait que parcourir successivement toutes les occurrences).
Existe-t-il une bibliothèque quelconque dans n'importe quelle langage de prog qui sache rechercher rapidement dans un gros PDF ? (et je foutrais des prompts pour forger une expression rationnelle, par exemple)
Jusqu'ici j'améliorais un peu le bordel en commençant par découper le PDF (parce que la liste des produits de fabricant X va de la page 1 à la page 223), ça améliorait la rapidité du ctrl+F mais refaire ça tous les mois... Je peux même pas faire un script automatisé pour ça (à supposer que ce soit possible) puisque le mois suivant, si ça se trouve, la liste des produits du fabricant X ira de la page 1 à la page 224...
Mon énoncé est peut-être un peu vague et confus, contactez-moi en mp si jamais vous avez des idées, je pourrais vous filer un échantillon du PDF pour mieux imager le truc.
Edit : peut-être une piste par là. http://search.cpan.org/dist/CAM-PDF/
Ptain, j'ai jamais fait de Perl moi
Edit 2 : notes à moi-même
http://qpdf.sourceforge.net/
http://pdfedit.cz/en/index.html
http://www.pdftron.com/pdfcosedit/index.html
http://www.unixuser.org/~euske/python/pdfminer/
http://www.pdftotext.net/

Affichage des résultats 7 561 à 7 590 sur 10008
-
10/06/2015, 21h54 #7561Tyranaus0r


- Ville
- Washington DtC
Dernière modification par Dark Fread ; 10/06/2015 à 22h25.
 Envoyé par O.Boulon
Envoyé par O.Boulon

-
10/06/2015, 23h45 #7562Homme de Goût

- Ville
- Toulouse
Bon, je développe, c'est vraiment pas terrible, déjà à cause du gros manque des features apportés par les "dernières" version de .NET (donc à partir de la 3.5, je te laisse voir les changelogs, mais en gros, tu perds WPF, tout l'abstraction asynchrone, le SIMD, pas mal de méthodes pour linq etc...). Envoyé par MetalDestroyer
Ensuite l'ide de xamarin est une atrocité absolue en terme d'ergonomie (je suis pas allé plus loin dans les features, mais ça me parait évident qu'il est difficile de faire mieux que VS)
Enfin, si c'est pour faire du dev sur mobile, autant le faire avec les langages natifs (surtout sur ios depuis qu'ils ont lâché l'Objective C, et java pour android, c'est à la portée de tout le monde). Envoyé par Snakeshit
-
11/06/2015, 14h09 #7563Son of Canardchie

- Ville
- A Courbet
En .Net et/ou Java : Envoyé par Dark Fread
http://www.codeproject.com/Articles/...F-to-Text-in-C
-
12/06/2015, 21h31 #7564Sous-titre ridicule

- Ville
- Lyon
Vous utilisez quoi comme logiciel gratuit pour faire un diff ? C’est pas forcément pour du code mais je demande ici

-
12/06/2015, 21h42 #7565:tournevis:

- Ville
- Blue team!
Donc, du C ou du C++ sur Androïd, on est bien d'accord? Envoyé par war-p
J'avais commencé un mooc sur Androïd mais j'ai pêté un cable à cause de Java...
-
12/06/2015, 22h13 #7566*X86 ADV*
Pour du fichier texte (sous Windows), j'utilise WinMerge. Envoyé par Frypolar
-
12/06/2015, 22h38 #7567Caneton

- Ville
- Toulouse
Meld Envoyé par Frypolar
Je l'ai découvert cet aprem, il est pas mal du tout
-
13/06/2015, 11h44 #7568*X86 ADV*

- Ville
- Rive droite
Histoire de compliquer, je recommande kdiff3, moi
")
Je le pratique depuis un moment, et ça fonctionne bien. Bons choix de design sur le merge 3-way.Sleeping all day, sitting up all night
Poncing fags that's all right
We're on the dole and we're proud of it
We're ready for 5 More Years
-
13/06/2015, 12h10 #7569Hardc0re

Idem que Tramb, j'utilise kdiff3. Pour les diffs et les résolutions de conflits dans git.
J'ai raison et vous avez tort.
-
13/06/2015, 12h15 #7570Tyranaus0r

- Ville
- in outer space
J'utilise soit WinMerge soit l'outil de comparaison intégré à Visual Studio + TFS.
-
13/06/2015, 13h15 #7571Homme de Goût
- Ville
- Toulouse
Non, C/C++ sous android n'est pas natif, avec le ndk, il est compilé vers du java Envoyé par vectra

 Envoyé par Snakeshit
Envoyé par Snakeshit
-
13/06/2015, 13h40 #7572:tournevis:
- Ville
- Blue team!
woput1 Envoyé par war-p

Bon, le développement mobile, je raye une fois pour toutes.
Et le système d'exploitation, il est compilé en java? Y doit bien y avoir un moyen de compiler des programmes C en natif, non?
-
13/06/2015, 14h02 #7573Roxx0r

De ce que j'ai compris le NDK permet d'embarquer des bouts de codes en C/C++. Mais le reste du programme tourne en Java. Il est d'ailleurs uniquement conseillé d'utiliser le NDK pour des tâches longues et qui demande beaucoup de performances (d'après leur site).
Depuis la dernière Google I/O, il semblerait qu'ils aient annoncé que le SDK serait ENFIN dispo en C++ (si j'ai bien suivi).
Et pour finir, oui il est possible de cross-compiler pour le linux de Android, d'après ce que j'avais lu y'a une toolchain quelque part, mais j'ai pas regardé plus que ça (pas encore) Envoyé par Keulz
-
13/06/2015, 14h03 #7574Homme de Goût
- Ville
- Toulouse
Je sais pas faudrait voir, mais ce qu'il fait retenir, c'est que le ndk a été fait après coup, et avec les pieds.
-
13/06/2015, 14h03 #7575*X86 ADV*

- Ville
- #10000, Baby.
C'est pas compilé vers du java.
"Dieu est mort" · "Si le téléchargement c’est du vol, Linux c’est de la prostitution."
-
13/06/2015, 15h50 #7576Tyranaus0r

- Ville
- Che suis alßaßien
Il est possible de compile des programmes qui tournent sur Android avec un simple cross compiler, mais à ce moment là il faut les uploader et les exécuter via SSH.
Pour avoir une application qui se lance via l'interface graphique il faut compiler ton programme en tant que DLL avec un point d'entrée qui s'appelle "ANativeActivity_onCreate", et ensuite créer un projet Java Android classique qui contient un p'tit morceau de code qui va charger ta DLL.
Le NDK quant à lui est une bidouille qui regroupe cross-compiler, librairies standards, et un système de makefiles à la con qui est censé automatiser le processus pour toi.Rust fanboy
-
13/06/2015, 16h11 #7577Tyranaus0r
- Ville
- Annecy
-
13/06/2015, 16h37 #7578Sous-titre ridicule
- Ville
- Lyon
Merci pour vos réponses, j’ai pris Meld, ça a l’air sympa et ça m’a suffit !
-
13/06/2015, 17h01 #7579Homme de Goût
- Ville
- Toulouse
Sophisme Envoyé par rOut
 Envoyé par Snakeshit
Envoyé par Snakeshit
-
13/06/2015, 18h19 #7580*X86 ADV*

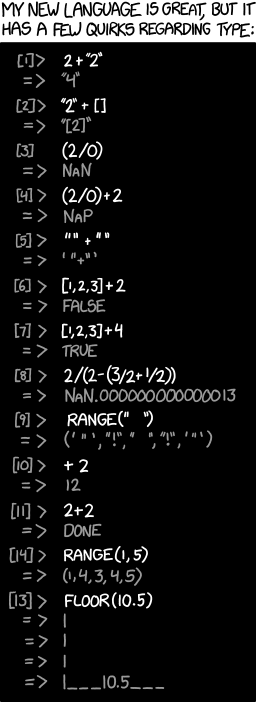
Je le trouve pas spécialement drôle pour le coup, ou alors j'ai pas compris les blagues. Le [8], j'ai essayé de refaire le calcul en base 3 sur des flottants de 29 trits, mais je tombe sur 1.000000000000015. Je pourrais aussi essayer en base 17, mais je pense qu'il a juste pris des nombres au pif. Envoyé par weedkiller

-
13/06/2015, 19h00 #7581Dr. Awakenstein

J'ai trouvé le floor(10.5) rigolo
.
-
13/06/2015, 19h15 #7582Highsc0re

Y'en a qui sont velues quand même:
Explain XKCD2+2 would normally be 4. However, the interpreter takes this instruction to mean that the user wishes to increase the actual value of the number 2 (aka the "literal value") by 2 for the remainder of the program, making it 4 and then reports that the work is "Done". The result can be seen in the subsequent lines where all 2s are replaced by 4s. This could be a reference to languages like Fortran where literals could be assigned new values.
Heureusement que y'as un wiki pour m'expliquer les blagues.
-
17/06/2015, 11h16 #7583*X86 ADV*
- Ville
- #10000, Baby.
Pour ceux qui ont raté le train :
http://www.zachtronics.com/tis-100"Dieu est mort" · "Si le téléchargement c’est du vol, Linux c’est de la prostitution."
-
17/06/2015, 15h58 #7584*X86 ADV*
- Ville
- Rive droite
T'es maléfique. La productivité du secteur va chuter encore plus. Envoyé par rOut
Sleeping all day, sitting up all night
Poncing fags that's all right
We're on the dole and we're proud of it
We're ready for 5 More Years
-
17/06/2015, 16h12 #7585*X86 ADV*
- Ville
- #10000, Baby.
C'est la crise mon pauvre ami.
"Dieu est mort" · "Si le téléchargement c’est du vol, Linux c’est de la prostitution."
-
17/06/2015, 16h21 #7586*X86 ADV*
C'est pas toi qui a posté le lien vers l'Underhanded C coding contest qui m'a fait perdre une après-midi de boulot ? Envoyé par Tramb
Merci, au fait.
-
17/06/2015, 16h33 #7587*X86 ADV*
- Ville
- Rive droite
Je suis innocent. De tout. Envoyé par Møgluglu
Et je ne connais pas ce TIS-100.Sleeping all day, sitting up all night
Poncing fags that's all right
We're on the dole and we're proud of it
We're ready for 5 More Years
-
17/06/2015, 21h21 #7588Son of Canardchie
- Ville
- A Courbet
C'est génial TIS-100

-
18/06/2015, 02h57 #7589Canardeur

- Ville
- Paris
Ami canard bonsoir,
Comme je sais que tout le monde ici vénère le python, j'en profite pour remettre le reptile sur la table.
Je travaille en ce moment sur une petite gui avec un système qui permet de connecter dynamiquement des morceaux de code. Cependant, j'aimerai permettre à l'utilisateur de pouvoir placer son module graphiquement dans l'application.
L'idéal serait quelque chose du genre :

J'ai bien trouvé OpenAssembler mais ça semble un poil abandonné (last update : 2009).
D'où ma question : Ne connaissant guère l’écosystème python, quelqu'un aurait-il sous le coude un (petit) framework pouvant si possible être inclut dans une interface pyQt ?
Bisous
EDIT : Bon, je vais partir sur bulbflow (je ne suis pas sur que ce soit ce que je recherche) mais si des canards ont des recommandations, je prends toujours!Dernière modification par Raplonu ; 18/06/2015 à 03h37.
-
18/06/2015, 10h59 #7590Canardeur
- Ville
- Paris
Trouvé! pyQtGraph a l'air de gérer ça plutôt simplement! Je vous montrerai le résultat
")




 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non