
Sur un CPU utilisant le modèle mémoire x86.Envoyé par fefe

Sur ARM, par exemple, toutes les requêtes ne sont pas nécessairement cohérentes, on peut très bien avoir des zones non partagées.
Sinon, pour le reste c'était très clair")

Affichage des résultats 271 à 300 sur 764
Discussion: Nehalem et innovations
-
22/09/2008, 10h45 #271*X86 ADV*

- Ville
- Vence
-
22/09/2008, 10h48 #272*X86 ADV*

OK pour les mécanismes de conservation de la cohérence du cache. Je ne comprenais pas trop pourquoi pour une lecture normale en cache on aurait eu intérêt à demander en 1er au L3 (ou LLC, c'est ça ? Last Level Cache ?)
Par contre, comment l'inclusion permet elle de savoir à partir de la présence d'une donnée en cache de niveau n qu'elle est également présente dans en cache de niveau n-1, n-2, et dans quel(s) core(s) précisement ? ("Si tes caches sont strictement inclusifs tu sais quel cores ont demande cette donnee et tu as meme des chances de savoir si ils l'ont encore.")
Ce sont des flags/tags qui permettent de savoir ça ?
Une politique de remplacement ne travaille que sur un seul niveau de cache ? Si une donnée est accédée en L1, la même donnée dans les niveaux supérieurs de cache n'est pas taggée comme récemment accédée ? Envoyé par fefe
Si ce n'est pas fait, je suppose que c'est parce que ca génèrerait un traffic énorme (une cohérence du LRU en gros...)
-
22/09/2008, 10h49 #273*X86 ADV Natif*

- Ville
- Far far away
Oui pardon, normal=x86 pour moi
.
fefe - Dillon Y'Bon
-
22/09/2008, 10h57 #274*X86 ADV Natif*
- Ville
- Far far away
Last Level Cache, Mid Level Cache, Data Cache Unit, Instruction Fetch Unit (LLC,MLC,DCU,IFU) sont les nom communement employes par Intel pour designer leurs hierarchies de cache. Envoyé par Yasko
Tu ne demandes jamais en premier au L3, tu demandes aux precedents niveaux, cela arrive au dernier niveau de cache que quand tu as des echecs. Il y a aussi le cas des ecritures coherentes, ou si tu n'as pas la donnee en mode exclusif dans ton L1 ou L2 il te faut demander l'ownership au L3 qui se chargera de verifier que personne d'autre n'a une copie modifiee.
Tu associes a chaque ligne de cache un vecteur de bit qui dit quel CPU y a accede, donc tu sais qui en a potentiellement une copiePar contre, comment l'inclusion permet elle de savoir à partir de la présence d'une donnée en LLC qu'elle est également présente dans des niveaux inférieurs de cache, et dans quel(s) core(s) précisement ? ("Si tes caches sont strictement inclusifs tu sais quel cores ont demande cette donnee et tu as meme des chances de savoir si ils l'ont encore.")
Ce sont des flags/tags qui permettent de savoir ça ?
Bien sur, la politique de remplacement est locale a chaque cache, sinon il faudrait transmettre des informations entre niveaux de caches a la meme vitesse que les acces au precedent niveau, ce qui detruirait l'un des interets des caches qui est l'economie progressive de bande passante a chaque niveau.Une politique de remplacement ne travaille que sur un seul niveau de cache ? Si une donnée est accédée en L1, la même donnée dans les niveaux supérieurs de cache n'est pas taggée comme récemment accédée ?
Si ce n'est pas fait, je suppose que c'est parce que ca génèrerait un traffic énorme (une cohérence du LRU en gros...)
Si le L1 repond a un hit, il va mettre a jour son LRU, mais ne dira rien a personne. Si il devait le dire au L2, il faudrait un lien qui a la meme bande passante que le L1 entre le L1 et le L2, et il faudrait un port dedie de mise a jour du LRU dans le L2 fonctionnant a la meme vitesse que le L1 (etc, etc si tu voulais le faire pour tous les niveaux de cache).
Ce n'est pas praticable, par contre rien n'empeche les caches d'envoyer de temps en temps quelques informations de LRU pour eviter que les niveaux superieurs ne vieillissent trop, mais je ne connais pas de constructeur qui a dit explicitement le faire, donc je doute qu'il y ait des implementations.fefe - Dillon Y'Bon
-
22/09/2008, 11h08 #275*X86 ADV*
Ok merki.
-
25/09/2008, 12h33 #276*X86 ADV*
Intel Core i7 (Nehalem) : une architecture signée AMD ? par Fedy Abi-Chahla (= fefe ?)
http://www.presence-pc.com/tests/Cor...tecture-22817/
-
25/09/2008, 13h35 #277*X86 ADV*

- Ville
- Dunkerque
C'est vrai que de Fedy à Fefe y'a qu'un pas, mais ce n'est pas lui.
Fefe bosse pas dans la presse info, en fait il est agent secret et a plusieurs fois sauvé le Monde (le vrai Monde, pas le journal).
Mais euh peut-être que je ne devais pas le dire ?
-
25/09/2008, 13h56 #278*X86 ADV Natif*
- Ville
- Far far away
Argh, je suis demasque !!!
fefe - Dillon Y'Bon
-
25/09/2008, 23h06 #279Sorcier Hardware

Rarement vu autant de conneries concentrées au même endroit. Le mec n'a visiblement même pas lu les présentations de base. Envoyé par Foudge

-
26/09/2008, 22h00 #280*X86 ADV*

- Ville
- Tours/Paris
\o/ Envoyé par Doc TB
-
26/09/2008, 23h51 #281*X86 ADV*
- Ville
- Dunkerque
il plaisante, vous devriez le connaître depuis le temps

-
27/09/2008, 09h50 #282Roxx0r
Ceci dit, il y a quand même des coquilles en dehors des présentations de base.
Pour le L3, l'auteur ne connait visiblement pas les Itaniums et les Xeons Netburst.Au premier abord la description fait invariablement penser à l’architecture Barcelona (K10) d’AMD : quad core natif, 3 niveaux de cache, un contrôleur mémoire intégré et un système d’interconnexions point-à-point à très hautes performances pour communiquer avec les périphériques et d’autres CPU dans des configurations multi processeurs. Ceci prouve bien que les choix technologiques d’AMD n’étaient pas mauvais en soit, c’est juste l’implémentation qui en a été faîte qui ne s’est pas avéré suffisamment compétitive.
Pour le second argument souligné, on ne comprend pas de quoi il parle : si c'est l'Hyper-Transport introduit par le K8, ou bien le L3 introduit dans le K10. Une personne avisée devine qu'il fait référence à l'implémentation du L3, car l'Hyper-Transport ne souffrait en rien d'un manque de compétitivité vu que c'est grâce à ça qu'AMD a grignoté des PDM dans les serveurs.
Sinon, on ne voit toujours pas en quoi un x-core non-natif est handicapant en soi, surtout pour les applications multi-threadées. C'est un délire de jeunesse.
Enfin, le contrôleur mémoire intégré, c'est Intel qui l'a testé en premier (Timna).
Une fois de plus, l'auteur semble ignorer l'histoire des Xeons : c'est le Prestonia qui a introduit l'HT, en février 2002, bien avant le P4B 3.06.C’est ainsi que le simultaneous multi-threading (SMT) déjà apparu avec le Pentium 4 Northwood sous le nom d’Hyper Threading signe son grand retour
C'est là que Sam explique pourquoi l'auteur n'a vraisemblablement pas lu la présentation de base : l'architecture est modulaire, ce qui signifie qu'on peut inclure davantage de cores sur le même die.Associé aux 4 cœurs physiques, certaines versions de Nehalem incorporant deuxdie sur un même package seront donc capables d’exécuter simultanément jusqu’à 16 threads !
Pour le reste de l'article, c'est un peu mieux. Je ne suis pas suffisament qualifié pour dire s'il existe aussi des coquilles dedans, mais j'aime bien la façon didactique de présenter la partie la plus difficile du sujet.
-
27/09/2008, 12h21 #283Sorcier Hardware
"Contrairement à ce que nous avions observé lors du passage du Core au Core 2, Intel n’a cette fois pas modifié en profondeur son front-end."

Tout le contenu de l'article est du copier/coller + paraphrase de la présentation sous NDA qu'a donné Ronak Singhal à Londres il y a deux semaines. Je le sais, j'y étais Sauf que les interprétations qu'il en fait sont souvent foireuses. En fait, les points qui sont correct dans l'article sont ceux expliqué par Ronak. Les autres sont soit bâclés, soit foireux.
Sauf que les interprétations qu'il en fait sont souvent foireuses. En fait, les points qui sont correct dans l'article sont ceux expliqué par Ronak. Les autres sont soit bâclés, soit foireux.
-
28/09/2008, 02h23 #284*X86 ADV*

- Ville
- Dead 2
C'est bon doc t'es en bonne voie, plus qu'à passer le lien du thread à l'intéressé et tu met Boulon à distance dans la compet' du droit de réponse Envoyé par Doc TB

Du coup, faut que fefe le prenne comment? Envoyé par Foudge
Il faudrait vraiment faire une encyclopédie du hard, ça rendrait bien service aux canards apprentis prêt à gober toutes les bêtises que l'on peut croiser sur le web.
-
01/10/2008, 14h39 #285*X86 ADV*
Intel next generation CPU Core i7 tested
http://en.hardspell.com/doc/showcont...35&pageid=3364
Là il n'y a rien de technique, c'est juste quelques bench
-
01/10/2008, 14h49 #286*X86 ADV*
Ca dépote sur la RAM...
-
01/10/2008, 16h29 #287*X86 ADV*

Ça rame dans les jeux...

La faute au contrôleur mémoire qui s'éloigne autant du GPU qu'il s'approche du CPU?
-
01/10/2008, 16h37 #288*X86 ADV*
Je dirais plutôt que dans les jeux, le Nehalem excelle autant qu'avant (à fréquence égale), mais c'est une question de point de vue
Et je pense que c'est plutôt à cause du SMT (certaines ressources sont partagées de manière statiques), du L1 un peu moins bon et un accès au LLC moins bon à cause de l'ajout d'un petit L2 privé et d'une taille diminuée (on passe de 2*6Mo à 1*8Mo).
Pour moi l'IMC est plutôt qqch de bénéfique pour les jeux.
edit: en plus de ça, comme c'est dit dans l'article d'HFR, le Nehalem a plutôt été pensé/optimisé pour une utilisation serveur, là où l'archi Core avait parfois du mal, pas pour les jeux et autre applis grand public où ça tournait déjà de manière excellente.
-
01/10/2008, 17h25 #289*X86 ADV*
- Ville
- Vence
Faut pas exagerer, on perd 10% en basse resolution ; qui joue encore en 1024x768 sans AA ?
Et puis il ne faut pas oublier que les drivers de carte graphique ont probablement besoin de pas mal de tuning car ca genere du code ces betes-la
-
26/10/2008, 21h22 #290Roxx0r
Elle approche le taped out : Envoyé par PeGGaaSuSS
http://downloadcenter.intel.com/Prod...=3018&lang=eng
-
26/10/2008, 22h04 #291*X86 ADV*
je l'ai reçue mardi c'te carte
Pas eu le temps de la tester encore alors que je devrais me grouiller vu que le NDA a été avancé de 15 jours
-
27/10/2008, 00h03 #292*X86 ADV*

- Ville
- Paris
Elle y était à la soirée Centrino 2. Le ventirad des Ci7 est bien bleu, il illuminait tout le boitier
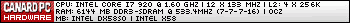
-
27/10/2008, 08h25 #293*X86 ADV Natif*
- Ville
- Far far away
Cote memoire il y a toujours un truc bien bizarre, 16GBps /25GBps c'est carrement mauvais pour un controleur memoire quand tu stream des acces sequentiels. Bien entendu c'est mieux qu'avant mais ca renifle le probleme (pas necessairement dans le hard, ca peut etre le bench qui est pourri et utilise pas le bon type de donnees, mais c'est le 2 eme bench qui est dans ce cas).
fefe - Dillon Y'Bon
-
27/10/2008, 08h34 #294Roxx0r
Ce n'est pas la première fois qu'Everest peut se tromper. Il m'est arrivé de trouver du 4 Go/s sur P4C là où on devait s'attendre à 4,8 Go/s, toujours avec le même Everest à l'époque (c'était encore Aida32 Envoyé par fefe
).
L'immaturité du bench vis-à-vis du bus QPI peut jouer aussi. Il émule peut-être un classique DMI là où il n'y en a plus (problème de flag sur plate-forme Intel).
-
27/10/2008, 08h53 #295*X86 ADV Natif*
- Ville
- Far far away
Le QPI n'est pas sur le chemin vers la memoire sur cette machine, donc ne devrait pas avoir d'impact sur la bande passante memoire (par contre pour les problemes de perf dans les jeux, oui tout a fait possible).
fefe - Dillon Y'Bon
-
30/10/2008, 00h50 #296Sorcier Hardware
Je m'excuse par avance des honteux raccourcis que je suis en train de faire sur l'article Nehalem, mais malheureusement, c'était indisponible pour que la majorité puisse essayer de comprendre le truc.
-
30/10/2008, 08h25 #297*X86 ADV*
- Ville
- Vence
L'embargo est leve lundi ? Je suis presse de lire tout ca, meme si c'est edulcore Envoyé par Doc TB
-
30/10/2008, 08h51 #298*X86 ADV Natif*
- Ville
- Far far away
Ok il te reste 1 option : Envoyé par Doc TB
- mettre des * dans l'article a chaque racourcis honteux
- ouvrir un topic ici qui explique pourquoi chaque * est un racourcis honteux (un peu comme les encadres tres techniques de certains de tes articles precedents).
De cette maniere tu garde ta credibilite, tu ne perds pas les non specialistes, et potentiellement tu eduques quelques curieux. En plus pour les explications du forum je suis sur que tu n'auras meme pas a tout faire et que certains s'en chargeront .
Si c'est trop de boulot de mettre des ancres dans les passages appropries de l'article, de toutes facons je suis certain qu'on ecrira qq chose ici pour expliquer a quel point ce journal est un scandale.fefe - Dillon Y'Bon
-
30/10/2008, 09h44 #299*X86 ADV*
Non, quadcore. Envoyé par newbie06

-
30/10/2008, 11h32 #300*X86 ADV*
Indisponible ? Et ce sera disponible quand ? Envoyé par Doc TB

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non