
Je crois qu'il va y'avoir qq'un qui va morfler chez Sun.

Affichage des résultats 91 à 120 sur 764
Discussion: Nehalem et innovations
-
26/02/2008, 11h13 #91*X86 ADV Natif*


- Ville
- Far far away
fefe - Dillon Y'Bon
-
26/02/2008, 19h52 #92*X86 ADV*
- Ville
- Liège (Belgique)
C'est vrai que du coup ça ressemble beaucoup à une carte pour Opteron. Envoyé par PeGGaaSuSS
Envoyé par PeGGaaSuSS

Je me réjouis de voir les perfs. Ca va faire très mal à AMD qui du coup n'auras plus vraiment un plus dans le monde server (les controleurs mémoire des Opterons sont appréciés pour les machines qui ont un nombre très élevé d'I/O)
La question qui a rien à voir : c'est quoi le chip video? Rien qui ressemble à un Volari z7 (une daube infame), ou ATI ES1000 sur un bus PCI 32bits...
-
26/02/2008, 21h05 #93*X86 ADV*

- Ville
- Paris
C'est un proto Intel, ca doit être du Intel j'imagine...
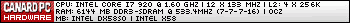
-
26/02/2008, 21h12 #94*X86 ADV*
- Ville
- Liège (Belgique)
Jusqu'à présent, il n'y a pas de gma intégré dans les chipsets serveur d'Intel...
J'ai un serveur Intel en test, c'est un ATI ES1000 pour le vga... (donc de l'AMD au sain même d'une config full Intel)
-
26/02/2008, 21h15 #95*X86 ADV*
- Ville
- Paris
Arf, j'ai toujours cru que c'etait les constructeurs de mobo qui chopait des vieux chips (pas idiot, moin cher, plus fiable).
Quoi qu'en fait, si les mobos sont une section séparé des CPU/chipset (chez Intel j'entends), ils peuvent faire ce qu'ils veulent...
Les mobos Intel ont parfois des choix bizarre la ou ca aurait pu être du full Intel!
-
11/03/2008, 13h13 #96*X86 ADV*

Leak d'un bench de Nehalem sur SPEC fait par Sun :

image de http://www.matbe.com/actualites/imprimer/32471/
http://blogs.zdnet.com/Ou/?p=1025
-
12/03/2008, 11h01 #97*X86 ADV*
- Ville
- Vence
Un truc me chiffonne (en dehors du fait des extrapolations faites pour obtenir les scores absolus par rapport aux scores relatifs du transparent de Sun) : le gars pretend qu'une partie du gain provient du SMT ; si c'est le cas, le score du Nehalem serait pour un 8 threads (SMT 2 x Nehalem EP 4 coeurs). Envoyé par Yasko
Si c'est bien le cas, on peut dire que cette comparaison ne tient plus la route.
-
12/03/2008, 14h10 #98*X86 ADV Natif*
- Ville
- Far far away
Vu que le slides contient des comparaisons entre dual core et quad core, et donc compare la perf/socket, cela ne me semblerait pas anormal si ils comptaient SMT dans leurs chiffres (et ca expliquerait au moins en partie les perfs tres hautes que montre ce graphe).
fefe - Dillon Y'Bon
-
12/03/2008, 17h29 #99*X86 ADV*
- Ville
- Vence
Et la consequence est : on ne peut rien deduire de cette comparaison sauf que c'est impressionnant pour un socket
")
-
12/03/2008, 17h42 #100*X86 ADV Natif*
- Ville
- Far far away
Si tu consideres un efficacite du SMT a la Prescott =~ 20%, ca te donne dans les 130-140 a une frequence inconnue, qu'on peut estimer similaire aux autres membres de la famille core (meme si differente il est peu probable que ce ne soit pas marginal), c'est a dire toujours plus haut que le shangai montre dans les 120.
IMO ca n'a plus rien d'impressionant (ca reste bon). Apres pour ce qui est des conclusions a tirer ca depend de ce qui t'interresse. Si c'est les performances sur des jeux modernes de Nehalem, effectivement je doute que ce graphe puisse repondre a quoi que ce soit (par exemple le P4 etait tres bon a SPEC et ca ne se traduisait pas en un avantage sur les jeux).fefe - Dillon Y'Bon
-
13/03/2008, 08h48 #101*X86 ADV*
- Ville
- Vence
Ce n'est pas necessairement une caracteristique de l'architecture, ca peut aussi venir d'un compilo tellement tune pour SPEC que la compilation du reste ne presente pas de bons resultats. Envoyé par fefe
J'ai souvent eu des discussions sur icc vs gcc, des gens pretendant qu'icc etait largement superieur a gcc. J'imagine que sur SPEC icc baffe mechamment gcc. Mon experience est que les gains sont en general de quelques % ("quelques" < 5%) dans un sens ou l'autre (pour des programmes deja tunes niveau C).
-
13/03/2008, 09h07 #102*X86 ADV Natif*
- Ville
- Far far away
icc est en general en avance pour la sortie d'optimisations correspondant aux archis des derniers microprocesseurs. La vectorisation SSE a ete disponible en premier sur icc dans mes souvenirs, mais aujourd'hui ce n'est plus un avantage parce que la majorite des compilateurs le font. L'architecture core/phenom n'a pas introduit de changements majeurs du point de vue du compilateur (par rapport a P6/banias/dothan/K8, il n'y a guere qu'a realigner le code pour des decodeurs 4-wide).
icc n'est pas vraiment meilleur que gcc sur les processeurs actuels, je suis d'accord, en pratique il est moins bon car il compile moins de codes que gcc (la compatibilite a ete amelioree mais ce n'est pas encore a 100%). Sur des benchmarks etablis il y a probablement un peu plus de tuning. gcc aussi est tune sur SPEC, mais je suppose qu'il y a tout de meme moins d'efforts faits que pour icc (AMD publie ses resultats SPEC en utilisant icc en general). Sur des gros codes j'ai vu 5 a 10% de perf pour icc avec PGO (rien de scientifique dans cette phrase), et l'effort necessaire a reussir a compiler ce code avec icc ne valait le coup que parce qu'on fait tourner des 10aines de milliers de process avec ce code.
Sinon , une fois mises de cote les optimisations specifiques des compilos pour SPEC, la plupart des programmes executes sur nos PC ont des caracteristiques tres differentes de SPEC. SPECFP rate a une tendance a etre limite par la bande passante memoire de la platforme alors que c'est le cas de tres peu d'applis client, SPECInt est a l'inverse extremement sensible a la prediction de branchement et a la taille du cache, bien plus que les jeux/encodeurs videos/logiciels de compression (peut etre autant que office, mais ce n'est pas comme si la performance sous office interessait encore grand monde).fefe - Dillon Y'Bon
-
18/03/2008, 08h48 #103*X86 ADV*
- Ville
- Vence
Puisque c'est le calme plat dans le secteur un petit lien :
http://www.anandtech.com/cpuchipsets...spx?i=3264&p=2
Reflexions apres lecture
-
18/03/2008, 20h12 #104*X86 ADV*

- Ville
- Dunkerque
Première remarque à chaud : pkoi M. Anand prend-il des photos de son écran au lieu de faire des copies d'écran ?
-
18/03/2008, 20h45 #105*X86 ADV*
- Ville
- Vence
Il y était, il se la pète Envoyé par Franck@x86

-
18/03/2008, 21h55 #106*X86 ADV*

Ça fait plus authentique
-
18/03/2008, 22h14 #107Roxx0r
C'est pour démontrer la puissance de son reflex 27 mégapixels avec supermacro premium
-
19/03/2008, 01h47 #108*X86 ADV*
- Ville
- Paris
Il avait oublié sa clef USB ?
-
19/03/2008, 14h35 #109*X86 ADV*

- Ville
- Suisse
Les slides : http://download.intel.com/pressroom/...efing_0308.pdf
Tic,Toc,blabla next....: http://www.intel.com/pressroom/archi...er_Nehalem.pdf
We should treat all the trivial things of life seriously, and all the serious things of life with sincere and studied triviality.[Oscar wilde]
There is no such thing as a moral or an immoral book. Books are well written, or badly written. That is all.[Oscar wilde]
No artist is ever morbid. The artist can express everything.[Oscar wilde]
-
20/03/2008, 11h45 #110*X86 ADV*
- Ville
- Dunkerque
Première CM Bloomfield :
http://www.xtremesystems.org/forums/...d.php?t=181181
-
31/03/2008, 08h33 #111*X86 ADV*
- Ville
- Vence
Les paris sont ouverts : http://realworldtech.com/forums/inde...88747&roomid=2
-
03/04/2008, 09h30 #112*X86 ADV*
- Ville
- Vence
Enfin des infos : http://www.realworldtech.com/include...719&mode=print
-
03/04/2008, 12h21 #113*X86 ADV Natif*
- Ville
- Far far away
Il detaille un peu les relations d'inclusivite/non inclusivite entre les caches
. C'est Franck qui va etre content.
fefe - Dillon Y'Bon
-
03/04/2008, 20h21 #114*X86 ADV*
- Ville
- Vence
Ca sent l'optim à la normande : Envoyé par fefe
(Il est pas beau mon piège pour obtenir des infos ?The L2 cache is neither inclusive nor exclusive with respect to the L1D cache. Like the Core 2, Nehalem can transfer data between the private caches of two cores, although not at full transfer rates.).
Il bosse chez Intel ?C'est Franck qui va etre content.
-
03/04/2008, 21h01 #115*X86 ADV Natif*
- Ville
- Far far away
Envoyé par newbie06
Non mais il aime les histoires de cache inculsif exculsif.
C'est pas de l'optim a la Normande c'est de l'optim a la Corse! Quand tu evicte qq chose du L2 du core 2 il ne va pas aller s'emmerder a snooper/invalider les L1 qui pourraient avoir une copie pour maintenir l'inclusion.fefe - Dillon Y'Bon
-
03/04/2008, 21h33 #116Randy 2016


et pour la cohérence ? Envoyé par fefe
Si 'autre core a besoin de l'info il faut qu'il tape en ram c'est ça ?Mes propos n'engagent personne, même pas moi.
-
03/04/2008, 22h06 #117*X86 ADV Natif*
- Ville
- Far far away
Le probleme de la methode corse est que ca force a snoop a chaque lookup du L2. Tu ne vas pas rechercher la donnee en RAM mais dans le bon cache. Par contre tu consommes bcp de bande passante a snoop. Envoyé par Neo_13
fefe - Dillon Y'Bon
-
05/04/2008, 15h39 #118*X86 ADV Natif*
- Ville
- Far far away
http://www.tgdaily.com/content/view/36758/135/
Plus de CPUs pour remplacer le GPU ? Mmm ca ressemble a du marketing agressif...fefe - Dillon Y'Bon
-
05/04/2008, 15h52 #119*X86 ADV*
- Ville
- Vence
Ouai et ça a du faire plaisir aux équipes qui bossent sur Larrabee
-
06/04/2008, 16h12 #120*X86 ADV*
Même si c'est pas mal de marketing, je suis assez d'accord avec Fosner. DirectX/OpenGL sont vraiment devenu complexes et se détachent de plus en plus d'un modèle de programmation cohérent. Ca ressemble de plus en plus a un amat de solutions ad'hoc! Envoyé par fefe
Cette semaine une vidéo à fait parler d'elle en illustrant les fonctionnalité apportés par DirectX10.1. Une des ces fonctionnalités utilisées à outrance est le rendu vers plusieurs cube map. Vas y que je te rajoute ça avec toute sa spec et qd ça peut être utilisé ou non, avec quel filtrage, quel état du pipeline, quel antialiasing, quel support est requis etc. Bref une fonctionnalité qui peut paraitre bien étrange pour quelqu'un qui code sur CPU (en se détachant de la spec des API) puisque lui il n'a pas eu l'idée qu'une Cube map ça devait être particulier (pour lui tout est un void*). La seule notion que je conaisse qui se rapproche de cette prog moins contrainte sont les Buffer Object d'OpenGL. (Un buffer object peut stocker n'importe quoi, Pixels, Textures, paramètres, Vertex etc.)
Bref tout ça pour dire que la prog sur CPU est qd même bien plus simple/souple. Par exemple, sur CPU, la notion de shader à la DX/OGL n'a pas lieu d'être en l'état puisque tout est programmable (Naïvement sur CPU, un shader = code ou milieu d'un boucle for). Le seul avantage des shader ala API graphique, c'est leur modèle de prog parallèle vraiment puissant (puisqu'invisible).
Puisque le GPU tend vers le calcul de plus en plus général et que le CPU tend à pouvoir accélérer du graphique ça ne me semble pas idiot de penser qu'a terme tout ça va s'unifier et qu'on aura donc plus d'API obscure ni de Proc dédié.
Sweeney soulignait dernièrement que le rendu soft était sans doute l'avenir (vu qu'il le dit depuis bientôt 5 ans ça atténue son impact). Je pense qu'il n'a pas forcément tord et qu'à terme, les CPU avec de plus en plus de cores vont pouvoir être utilisés pour avoir des très bonnes perfs en rendu soft et ce sans les limitations des API. Il faut bien comprendre que le rendu sur CPU n'a aucune limitation conceptuelle. Pas besoin d'attendre le matos et la spec qui va avec pour pouvoir profiter de tel ou tel algo.

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non