
C'était juste pour répondre à ça :
Après que ce soit performant ou pas est une toute autre affaireEnvoyé par fefe

")

Affichage des résultats 2 821 à 2 850 sur 2889
Discussion: News en tout genre...
-
28/04/2010, 22h24 #2821*X86 ADV*

- Ville
- Vence
-
29/04/2010, 02h19 #2822*X86 ADV Natif*

- Ville
- Far far away
Oui, je me souvenais qu'on ne pouvait pas, mais ma memoire etait affectee (faussee) par des considerations de performance et par le fait que quasiment personne n'active ce mode pour quoi que ce soit.
fefe - Dillon Y'Bon
-
29/04/2010, 20h56 #2823*X86 ADV*

Moi, je dis qu'il faut essayer.
Qui c'est qui se dévoue pour hacker un Linux en lui faisant mapper la mémoire user sur la mémoire vidéo?
-
29/04/2010, 21h45 #2824*X86 ADV*

- Ville
- Lorient (56)
Ca a déjà été fait,refait et rerefait. Envoyé par Møgluglu
Je crois que j'avais déjà lu un papier dans MISC qui expliquait comment faire il y a au moins 5 ans, si ce n'est pas plus.
A noter qu'il y a dans le même style la vulnérabilité 'Firewire' qui est aussi très drole (ou comment passer outre toutes les protections aussi bien d'un windows que d'un linux du moment qu'il y a un driver firewire et un accès physique au port).... There are only 10 types of people in the world: Those who understand binary, and those who don't.
There are only 10 types of people in the world: Those who understand binary, and those who don't.
-
29/04/2010, 21h57 #2825CPC Hardware
Y a des pilotes pour créer des "ramdrive" en mémoire vidéo. Envoyé par Møgluglu
-
29/04/2010, 22h25 #2826*X86 ADV*
Oui, le ramdrive en mémoire vidéo c'est facile et je l'ai déjà utilisé.
Mais là je cherche un moyen d'éviter cette aberration qu'est créer un ramdrive pour l'utiliser comme swap, et rendre la mémoire directement adressable par les programmes en mode user, au moins pour faire tourner quelques benchmarks pour savoir de combien c'est plus lent que la mémoire locale.
Wanou, si tu as des refs (un peu plus précises) je veux bien.")
Même si j'imagine bien que c'est pas compliqué, c'est jamais qu'une autre plage d'adresse en mémoire physique...
-
30/04/2010, 11h58 #2827*X86 ADV*
- Ville
- Vence
"mmap frame buffer" sous google ne donnerait-il pas ce que tu cherches ?
Bien sur il faut etre encore sur que le driver ne cree pas un fake FB
Sur la PS3, la RAM du GPU peut etre utilisee comme swap.
-
30/04/2010, 16h10 #2828*X86 ADV*
- Ville
- Lorient (56)
Voilà, j'ai retrouvé une partie du papier: C'était un papier de Loic Duflot de 2006.
Il s'agissait d'utiliser la mémoire vidéo en conjonction avec le SMM pour obtenir un root access.
http://www.securityfocus.com/columnists/402/3
Pas moyen de retrouver le PDF de la présentation sur la site d'origine.
(on trouve les slides http://www.cansecwest.com/slides06/csw06-duflot.ppt ) mais j'espérais quelque chose de plus détaillé.There are only 10 types of people in the world: Those who understand binary, and those who don't.
-
30/04/2010, 16h16 #2829*X86 ADV*
- Ville
- Vence
http://www.ssi.gouv.fr/archive/fr/sc...flot-paper.pdf
Mais ca a l'air de plutot parler des reg I/O que de la VRAM.
-
30/04/2010, 17h09 #2830*X86 ADV*
Merci pour le lien (tiens, encore un papier d'un pote à fefe).
Ouais je vois l'idée: les registres de conf SMI sont mappés dans la même zone que la mémoire vidéo "legacy", qui est accessible à X sous BSD, ce qui permet une élévation de privilège.
Mais sous Linux c'est pas un problème, vu que root a accès à tout. Il suffit de mapper la plage d'addresses qui va bien (celle de la vraie mémoire vidéo) dans /dev/mem, et de jouer avec les MSR et/ou la PAT pour rendre ça cachable.
Enfin y'a rien de déjà tout fait, et là mon chef est en train de me regarder méchamment, je sais pas pourquoi...
-
12/05/2010, 10h54 #2831*X86 ADV*
- Ville
- Vence
Otellini : http://www.techeye.net/chips/intels-...ghtened-by-arm
Il se touche la nouille ou bien le site a mal retranscrit ?He said that Intel has shipped 3.3 billion processor cores in Q1 2010. By the end of this year that number will be closer to four billion cores.
-
12/05/2010, 11h06 #2832*X86 ADV*
Hint: l'auteur de la news a longtemps été rédac' chef de The Inquirer...
Ça ressemblerait plutôt à un total cumulé de cores x86 vendus jusqu'ici... Et qu'ils prévoient de vendre 700 millions de cores d'ici la fin de l'année?
-
12/05/2010, 11h09 #2833*X86 ADV*

Oui c'est comme ça que je l'ai compris, sinon ça n'a pas de sens : 3.3 milliards en 3 mois (n'importe nawak de toute façon) et "seulement" 4 milliards en un an ? Envoyé par Møgluglu
-
12/05/2010, 11h09 #2834*X86 ADV*
- Ville
- Vence
Oui je pense comme toi que ce serait plutot :
EDIT : d'ailleurs ca parle de coeur et pas de chip, ce qui bien entendu cree une inflationHe said that Intel has shipped 3.3 billion processor cores by Q1 2010. By the end of this year that number will be closer to four billion cores.
-
12/05/2010, 11h22 #2835*X86 ADV*
Oui, d'ailleurs je suis sûr qu'après la sortie de Larrabee auprès du grand public, Intel se fera un plaisir de nous montrer de belles courbes qui montent vachement plus vite tout d'un coup
-
12/05/2010, 18h59 #2836*X86 ADV*
En nombre d'unités / an :
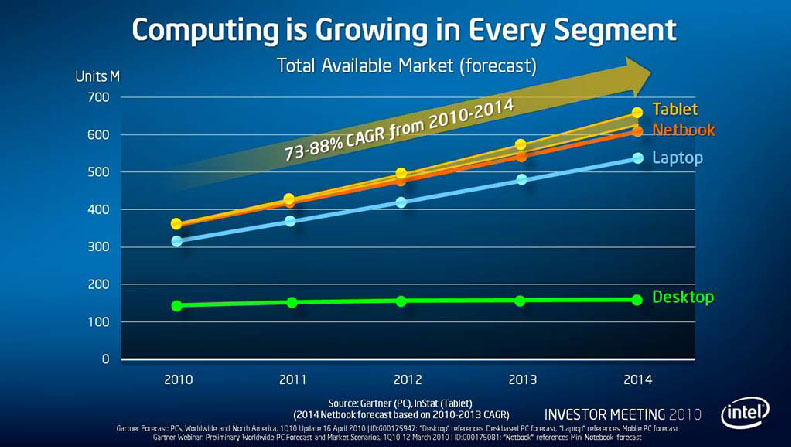
Les courbes représentent bien sûr les sous-totaux, faut pas les additionner...
Intel prévoit donc que le marché des tablettes va partir de rien pour arriver à pas grand-chose, et qu'en fait c'est surtout le marché du laptop qui serait en augmentation...
-
12/05/2010, 19h27 #2837*X86 ADV*
Ils semblent également penser qu'on vendra moitié autant de netbooks que de desktops... Personnellement, je pense plutôt que les netbooks (au sens de laptop pas cher et bon à rien d'autre qu'à la navigation sur le web) vont dégringoler. D'ailleurs on dirait que ça commence...
-
12/05/2010, 22h32 #2838*X86 ADV Natif*
- Ville
- Far far away
Je dirais que la prevision est probablement bonne pour la somme netbook+tablets, mais rien ne dit que 100% de ca ne sera pas des tablets... Je doute que les desktop restent constants.
Honnetement un desktop ne devrait plus servir a grand chose le jour ou on pourra avoir des docking stations avec des specs comme ca:
- connectique standardisee entre la docking station et le laptop/netbook/tablet (USB-X?) qui fournit le power ET les echanges de donnees.
- stockage additionnel/backup (probablement sous forme de disque dur alors que l'appareil mobile emploie de la flash) dans le dock
- "accelerateur" dans le dock, come une bonne grosse carte graphique discrete (ou un plus gros CPU si ca sert a quelque chose), pour te permettre de jouer, ou de faire des taches trop lourdes pour le processeur de l'appareil mobil
- toute la connectique fil/sans fil necessaire aux nombreux peripheriques/interfaces qui trainent sur le burau. Ca pertmettra a l'appareil mobile de ne plus avoir tous ces ports a la con qui prennent de la place et ne servent quasiment jamais.
J'utilise tous les jours un laptop docke que je me trimbale partout. C'est pratique sauf que tous les docks sont proprietaires et que la gestion des procedures de dock/undock est completement foireux et merde beaucoup trop souvent. Si on reussit a faire des docking stations avec les 3 caracteristiques cis-dessus (on peut eventuellement ajouter une connectique standardisee pour l'evacuation de la chaleur du boitier, mais je ne reve pas), il n'y aura plus vraiment de raisons d'avoir un desktop en dehors de quelques rares personnes.
Avec un SSD dans mon laptop et mon desktop, et 4G de memoire dans chaque et 4 threads sur chaque je ne vois honnetement aucune difference a l'utilisation, la seule tache qui les fasse souffrir, c'est convertir en batch des tonnes de RAW et les quelques centaines de MHz de moins de mon laptop ne sont pas vraiment un handicap.
Bref, mon desktop actuel risque d'etre mon dernier, le jour ou je peux jouer en full HD quand je dock mon laptop et ou j'ai un backup rapide et transparent en tache de fond a chaque fois que je dock (et acces et ma bibliotheque de media qui pour l'instant est sur un NAS).fefe - Dillon Y'Bon
-
18/05/2010, 09h36 #2839*X86 ADV*
Le Charlie nouveau est arrivé :
http://www.semiaccurate.com/2010/05/...ow-larrabee-2/
Le débat est ouvert pour savoir ce que peut bien signifier 'converged pipeline'.
Moi je verrai bien une ISA scalaire uniquement, compatible x86, exécutée en SIMT.Spoiler Alert!
-
18/05/2010, 10h15 #2840*X86 ADV*
- Ville
- Vence
J'ai rien compris
Leur "converged pipeline" ca serait pas des ressources partagees par des ISA differentes ?
-
18/05/2010, 10h35 #2841*X86 ADV*
Une archi comme celle de NVidia. (mais avec du x86, bien sûr Envoyé par newbie06
)
Ça doit plutôt être un truc comme ça au final.Leur "converged pipeline" ca serait pas des ressources partagees par des ISA differentes ?
-
19/05/2010, 02h50 #2842*X86 ADV Natif*
- Ville
- Far far away
Je pense que la convergeance dont il parle est a un tout autre niveau que celui auquel tu pense (c'est une maniere bizarre de voir les choses si il refere a ce a quoi je pense). Envoyé par newbie06
Oui, oui j'essayerai de faire encore plus cryptique la prochaine fois...fefe - Dillon Y'Bon
-
19/05/2010, 10h03 #2843*X86 ADV*
Vas-y, dis tout de suite que je suis bizarre. Envoyé par fefe

Je ne sais pas si je pense à ce que fefe pense que je pense, mais je voyais un truc du genre du slide 83 de la présentation d'Andy Glew à Berkeley :
http://parlab.eecs.berkeley.edu/site...lew-vector.pdf
(un peu technique, mais une des docs publiques les plus intéressantes sur les archis parallèles... et assez déprimant à lire quand on pensait avoir plein d'idées et qu'on voit qu'à chaque fois il y a pensé, en mieux.)
-
19/05/2010, 16h13 #2844*X86 ADV*
- Ville
- Vence
Encore un site qui a mal retranscrit ce qu'a dit Otellini, ou bien encore un tripotage de nouille intempestif ?
http://www.eetasia.com/ART_880060708...T_09ce0918.HTM
En un an, ARM a vendu plus de 4G CPU, ca m'etonnerait qu'il y ait autant de x86 en circulation ; d'ailleurs plus loin Otellini aurait dit "over its entire history Intel had shipped 3.3 billion processor cores by the end of Q1".Otellini said: "All architectures live under the same laws of physics. There's nothing unique about ours or theirs. At the end of the day it is the quality of the architecture and the quality of the implementation of the silicon it goes on. Today we have the most popular architecture in terms of the installed base of cores and the best silicon in the world."
Ou alors l'utilisation de base au lieu de number est la pour introduire une ambiguite.
Faut que j'arrete de lire ces conneries, ca me deprime.
-
19/05/2010, 17h35 #2845*X86 ADV Natif*
- Ville
- Far far away
L'intro est typique d'Andy Envoyé par Møgluglu
.
Slide 83: c'est bien de partager la urom, mais pour partager le decodeur il faut stocker les instructions decodees dans un cache/trace cache de taille suffisante, sinon aucun decodeur x86 n'aura le throughput requis et il faudra repliquer le decodeur (et la ca devient une mauvaise idee).
Si tu executes ton code SIMT de maniere concurrente avec du code x86 legacy, tu rencontres assez vite les problemes de code auto-modifiant qui te forcent soit a flush ton cache d'instruction pre-decodees soit a implementer des mechanismes complexes de tracking qui te permettent de rtrouver qui est decode ou...Dernière modification par fefe ; 19/05/2010 à 17h45.
fefe - Dillon Y'Bon
-
20/05/2010, 13h20 #2846*X86 ADV*
Ou bien il parle des développeurs qui n'ont jamais testé leur code sur autre chose que du x86, et de ceux qui utilisent des bibliothèques qui dépendent de bibliothèques qui tournent sur des OS qui ne sont disponibles que sous x86 pour diverses raisons politiques. Envoyé par newbie06
Là je ne te suis pas... Envoyé par fefe

Au départ l'idée du SIMT (ou du SIMD ou du vectoriel) est justement d'amortir le coût du décodage en faisant plus de calculs par instruction décodée...
Si j'exécute une multiplication sur un warp de 16 threads, je n'ai besoin de décoder l'instruction qu'une seule fois et je maintiens mon multiplieur SSE 4-way (légèrement modifié) occupé pendant 4 cycles.
Ou tu te places dans le cas d'une implémentation comme le SSE sur le Pentium-M, où une instruction SIMD/SIMT est éclatée en plusieurs uops qui sont dispatchées comme d'habitude?Dernière modification par Møgluglu ; 20/05/2010 à 13h36.
-
20/05/2010, 17h38 #2847*X86 ADV Natif*
- Ville
- Far far away
Si les PC de chaque thread sont parfaitement synchrones et que tu n'as pas de branchements, il n'y a effectivement pas de problemes de throughput de decodage: les decodeurs gerent deja correctement le cassage en multiples uops de chacune des instructions et sont correctement dimensionnes. Je realise que ce a quoi je referais est plus proche de SPMT, single (short) program multiple threads. Tu fais aussi beaucoup plus de calculs par instruction decodee mais garde une certaine flexibilite (et il faut que tu caches tes instructions decodees).
Dans le mode strict SIMT et uniquement FP, la separation en uop n'est pas particulierement un probleme.fefe - Dillon Y'Bon
-
20/05/2010, 19h00 #2848*X86 ADV*
OK, genre comme les slides 46 et 47 de Glew (un loop buffer indépendant pour chaque voie SIMT avec quelques instructions prédécodées)?
Mon impression, c'est que si on ajoute de la flexibilité en désynchronisant les threads, on risque aussi de perdre en cohérence (au sens de régularité) dans les accès mémoire...
C'est probablement à cause de ça que Glew met un (petit) cache de données par voie SIMT, contrairement aux GPU actuels.
(oui, on serait mieux sur le topic micro-archi...)
-
20/05/2010, 19h14 #2849*X86 ADV*
Ici le terme "converged core" est utilisé dans le sens "one core to rule them all" :
http://pc.watch.impress.co.jp/docs/c...21_368266.html
Ce qui semble donner raison à newbie...
(ou alors c'est Charlie qui mélange tout)
-
20/05/2010, 19h19 #2850*X86 ADV Natif*
- Ville
- Far far away
Oui et non, tu peux partager ce cache d'instruction decodees (ou loop buffer) ou le dupliquer suivant le degre de flexibilite recherche entre les threads.
---------- Post ajouté à 19h19 ----------
Historiquement le terme converged core a ete utilise a Intel pour designer le fait de reutiliser un core dans des segments auxquels il n'etait pas destine: ex Merom a finit dans des desktops et server. Envoyé par Møgluglu
fefe - Dillon Y'Bon

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non