
Plop,
Je n'ai pas vu de sujet parlant du Raytracing et surtout des architectures "dédiées" qui semblent poindre à l'horizon pour supporter ce type de calcul graphique. Notamment les architectures futures de Nvidia (voir CPC no 384).
J'ai pas mal de question sur le sujet qui ont émergé en lisant l'article CPC, ayant un peu codé sur les cartes graphiques, et en maitrisant un peu l'architecture matérielle et le comportement dans les projections 3D, j'ai vraiment du mal à voir comment Nvidia a optimisé le bouzin ? Je m'explique :
- Le problème de la propagation de rayon (ou plutôt de la projection de la scène) est déjà résolu par le hardware et le software de la carte graphique, les cartes graphiques sont conçue pour ça à l'origine après tout.
- Le Raytracing revient théoriquement à la même chose que relancer un rayon à chaque obstacle et à recalculer sa propagation. Ce qui revient strictement à calculer la projection de la scène selon un autre point de vue. (ce que fait nativement la carte graphique, une fois encore, mais évidemment à chaque fois qu'on fait ça on multiplie le cout de calcul)
- Une architecture optimale pour le Raytracing ne serait-elle donc qu'une grosse carte graphique, mais strictement identique en dehors de ça
Tout ceci n'est pas clair pour moi, ai-je oublié un truc ?(je suis amateur dans le domaine malgré mes expériences de code sur carte graphique, ce n'est pas ma spécialité, mes cours sont loin dans ma tête) et les algos de raytracing n’emploieraient-ils pas du tout une projection de rayon similaire au calcul matriciel de projection déployé classiquement sur les cartes graphiques ? Nvidia aurait il effectué une percée théorique dans le domaine ? Ou alors il n'y a ni véritable percée théorique, ni véritable percée architecturale et s'est t-il contenté de pondre une immense carte graphique ?
Je précise que j'exclue de ma question la réduction de la complexité du calcul via des algos tiers appliqués après coups, je suis au courant de l'emploi d'un post-filtrage à base de réseau de neurone pour diminuer les paramètres de qualité du raytracing et économiser le rendu (voir CPC no 384), mais là je ne parle qu'a complexité donné, comment le calcul a été simplifié architecturalement et algorithmiquement tout seul.
Si je devais résumer mes questions en une seule phrase, disons : Comment le raytracing a t-il été (ou l'a t-il été ?) simplifié algorithmiquement ou architecturalement par rapport à la méthode classique de projection de scène (ou de lancer de rayon, selon le point de vue) existant déjà depuis perpet ?
Voila pour mes questions initiales, mais le topic peut accueillir toutes les news et autres débat relatifs au sujet des archis ou des algos de raytracing. Évidemment
Voili voilou !

Affichage des résultats 1 à 30 sur 61
Discussion: Ray-Tracing et architectures hardwares dédiées
-
16/08/2018, 02h27 #1Tyranaus0r


- Ville
- Une chrysalide
Dernière modification par Nilsou ; 16/08/2018 à 02h45.
-
16/08/2018, 14h02 #2Tyranaus0r


- Ville
- faquin !
J'avais fait un prototype de raytracing sur GPU pendant mon master en heuuuuu 2006 je crois. :vieux:
J'ai plus trop suivi l'évolution sur les techniques de rendu, mais a moins que ça ait fondamentalement changé, on n'utilise à aucun moment le pipeline de rendu classique pour ce genre de calcul (bon à l'époque on l'utilisait de manière détournée pour faire du gpgpu car pas d'autre choix mais c'était du bricolage et on n'utilisait directement aucun mécanisme de rendu en tant que tel).
Imagine la complexité si pour chaque pixel il fallait recréer la projection d'une scène complète (et récursivement pour chaque rebond sur plusieurs niveaux de profondeur...).
Le raytracing, on lance un rayon pour chaque pixel de la fenêtre de rendu, on calcule les intersections, quand on en trouve une on lance les rayons secondaires :
- un rayon vers chaque source lumineuse pour l'éclairage direct
- un rayon symétrique pour l'éclairage indirect ou les réflexions selon le matériau
- éventuellement un rayon réfracté pour les matériaux transparents
C'est fondamentalement différent de la rastérisation qui manipule uniquement les sommets dans l'espace 3D et crée les surfaces après projection dans l'espace 2D de la fenêtre de rendu. Dans le raytracing, on doit prendre en compte les surfaces dans l'espace 3D.
Les GPUs sont très bon pour ça naturellement : des calculs de type vectoriel totalement indépendants mais sur une grosse structure de donnée commune à tous les calculs on fait difficilement mieux adapté.
Le gros soucis c'est que le raytracing a une exécution imprédictible : selon les matériaux rencontrés on va avoir à gérer plus ou moins de rebonds sur plus ou moins de niveaux. Les derniers GPUs sont pas mal pour ça car ils gèrent assez bien les charges de calcul variables. A part ça je ne vois pas de grosse évolution dans ce domaine particulier. Pour le coup cette histoire de filtrage basé sur le deep-learning ça me semble un très bon moyen pour garder une qualité élevée en limitant fortement le nombre de niveaux de rebonds à gérer donc la complexité. C'est peut-être la plus grosse avancée pour le temps-réel.
EDIT : du coup je viens de jeter un oeil, Nvidia a annoncé il y a deux jours l'architecture Turing qui va apparemment contenir des "RT cores" spécialisés poru le calcul des intersections et la traversée des structures. Effectivement si on a des unités de calcul spécialisées pour cet unique aspect ça peut aller beaucoup plus vite.Dernière modification par Lazyjoe ; 16/08/2018 à 14h46.
"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
Envoyé par Sidus Preclarum

-
16/08/2018, 21h12 #3Tyranaus0r
- Ville
- Une chrysalide
Merci pour ton retour
") mais j'ai du mal à voir en quoi plusieurs des points de ton explications ne correspondent pas exactement au pipeline standard.
mais j'ai du mal à voir en quoi plusieurs des points de ton explications ne correspondent pas exactement au pipeline standard.
Par exemple le :
- un rayon vers chaque sources lumineuses pour l'éclairage direct
est strictement équivalent au calcul classique de l'illumination qui revient à projeter la scène du point de vue de la source lumineuse primaire. (les rayons vont dans l'autre sens, mais c'est la même sinon, il y a autant de rayon, edit : quoique avec la rasterisation on éclaire des endroit non visible ni en lien pour l'observateur, en effet... )
quand tu parle de :
- un rayon symétrique pour l'éclairage indirect ou les réflexions selon le matériau
Qu'entends tu par "symétrique" ? Et comment gérer l’éclairage diffus dans ce cas si un seul rayon est lancé par endroit touché ?
Mais du coups si je suis bien, il n'y a à chaque fois qu'un rayon de lancé ? Moi qui pensais naïvement que chaque surface devenais une source lumineuse secondaire ... (et dans ce cas autant utiliser la resterisation itérativement) On est encore loin de la réalité du coups
On est encore loin de la réalité du coups
N'y a t-il pas un soucis de variation excessive du résultat en fonction de la position de la personne ? Vu que les rayon sont lancés depuis l’œil de l'observateur ... (surtout avec peu de rebond, on imagine sans mal que dans une position on atteint en quelques rebonds une source lumineuse, mais pas dans une autre ...)
Comment ça se passe d'un point de vue algorithmique pour écrire un lancé de rayon du point de vue des shaders ?
-
16/08/2018, 22h21 #4Tyranaus0r
- Ville
- faquin !
Strictement équivalent dans le monde continu, c'est pas faux. Mais en pratique on crée une fenêtre de rendu au niveau de la source lumineuse et donc on crée une lightmap dont les pixels ne correspondront pas du tout avec ceux du point de vue de la caméra (à moins d'être superposés). D'où les gros effets de crénelage sur les ombres dans les jeux. En raytracing tu es sûr de calculer la visibilité d'une source lumineuse pour le point exact ciblé par un rayon, aucun crénelage indésirable possible. Envoyé par Nilsou
Bah juste symétrique par rapport à la normale. Mais effectivement il n'y a pas de notion d'éclairage diffus en fait, c'était un abus de langage de ma part. Si je ne m'abuse c'est plus ou moins simulé en définissant des surface mates pour les rayons partant vers les lumières, mais légèrement réfléchissantes pour le rayon partant vers les autres objets par exemple. Envoyé par Nilsou
Bah oui, le raytracing reste une méthode purement locale et chaque rayon est calculé indépendamment de ses voisins. C'est quand même un gros cran au-dessus de la rastérisation car tous les calculs sont effectués dans l'espace 3D. Quand on voit un pixel ray-tracé, on sait que c'est bien le point de la surface de l'objet dans la direction de la caméra qui est affiché (alors qu'en rastérisation ce n'est vrai que pour les sommets des triangles, les pixels intérieurs étant interpolés après la projection). Envoyé par Nilsou
D'ailleurs les sources lumineuses restent ponctuelles, le raytracing ne va pas permettre de calculer le halo d'un éclairage étendu comme un néon par exemple.
Pour de la véritable illumination globale il y a plein d'autres méthodes beaucoup plus lourdes en calcul. Par exemple la radiosité où on exprime les relations entre les différentes surfaces sous forme d'équations et on applique une méthode de montecarlo pour résoudre l'ensemble du système, ou encore le photon mapping où chaque source lumineuse va émettre une distribution de photons qui vont parcourir la scène ce qui est une forme de ray tracing à l'envers pseudo-continu.
C'est justement le problème que le filtre deep-learning de nvidia semble résoudre efficacement. Envoyé par Nilsou
Ben heu niveau shader ça ne se passe pas, vu que les shaders c'est un mécanisme du pipeline de rasterisation qui est totalement l'opposé du raytracing. Envoyé par Nilsou
"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
16/08/2018, 23h02 #5Tyranaus0r
- Ville
- Une chrysalide
C'est pas faux, j'avais oublié ce soucis ... Envoyé par Lazyjoe
Oui mais d'un autre coté avec suffisamment de triangle le soucis est très faible. Et la rasterisation à l'avantage d'utiliser sa méthode de projection pour projeter les sources lumineuses vers toutes les surfaces, même non vu par le joueur. En clair, la gestion des reflets coute cher, mais l'illumination initiale est proche de la réalité (source de lumière directe), et est absolument stable (ne dépends pas de la position du joueur). J'ai pas l'impression, d'après ce que tu dis, que c'est le cas sur le raytracing... Envoyé par Lazyjoe
Bien dommage du coups ^^ Envoyé par Lazyjoe
Ben tu vois j'ai un doute, c'est un peu mon domaine d'expertise et j'ai eu l'impression dans l'article CPC que ce filtre semble conçu pour résoudre le problème du bruit de sous échantillonnage sur image fixe. Envoyé par Lazyjoe
Pourtant de ce que tu décris du raytracing, le problème me semble bien plus gros au niveau du rendu dans un environnement étendu (les reflets lointain des rayons étant probablement bien inutile pour l'observateur et le sous échantillonnage régulier dans un petit environnement risque d’être fort irrégulier dans un environnement étendu non ? D'ailleurs les exemple de raytracing pour le moment sont en intérieur, de ce que j'ai vu ...) et surtout la solution ne semble pas du tout stable selon le point de vue. (donc on doit avoir un sale effet de variation lumineuse ou de clignotement lorsqu'on bouge). Ces deux soucis me semblent difficile à résoudre avec le deep learning, alors que le premier (petit sous échantillonnage de taille fixe (donc forcement en environnement clos dans le cas du raytracing)) c'est l'enfance de l'art.
Comment comptent t-ils afficher des scenes lointaines un brin complexe avec ces limitations ? J'ai un peu de mal à voir ...
- - - Mise à jour - - -
Hum, j'ai du mal à saisir, pour moi les shaders sont justes des petits bouts de programme du pipeline, certes, mais qui sont aujourd'hui ultra generaliste et peuvent presque être utilisé en directe pour le calcul parallèle. Envoyé par Lazyjoe
Du coups je reformule : comment écrire sous forme de petit programme exploitant les calculs massivement parallèle de la CG un lancer de rayon ? Parce que comme ça j'ai quand même l'impression que l'algo est très séquentiel, rayon par rayon je veut dire ...
-
17/08/2018, 02h12 #6Tyranaus0r
- Ville
- faquin !
Ben heu si pour le coup les phénomènes d'éclairage direct sont indépendant de la caméra, vu que le rayon entre un point de la surface et une source lumineuse est totalement indépendant de la caméra. Après l'angle ente ce rayon et le rayon caméra-objet peut servir à calculer une composante spéculaire sur la lumière qui variera en fonction de la position de la caméra, mais c'est pareil en rastérisation. Envoyé par Nilsou
Après ce que tu décris pour la rastérisation c'est plutôt un désavantage. Tu dois te taper un rendu de scène complet pour générer une shadowmap, qui par définition ne couvrira qu'une partie de la scène, donc potentiellement à la fois trop et trop peu de choses, avec une résolution limitée et qui prend de la place en mémoire. Bon après effectivement si tu as une scène où les lumières et objets sont fixes tu peux te contenter de précalculer les shadowmaps et tu aura juste à les plaquer lors du rendu ce qui sera très rapide et le standard dans les jeux depuis longtemps. Je me souviens dans half-life c'était encodé directement dans les maps, et une grosse partie du temps passé par l'éditeur de niveau pour générer les fichiers était dû aux shadowmaps.
En fait je pense que tu ne vois pas bien comment fonctionne la rastérisation dans le fond. C'est une technique de rendu qui ne manipule strictement que les phénomènes directs. On a des sommets avec des normales, on calcule l'éclairage des sommets en fonction de l'angle de la normale avec les lumières, on projette cette couleur dans l'espace caméra, on remplit les pixels entre les sommets projetés d'un même élément géométrique. Et c'est tout. Il n'y a pas d'ombres portées, de réflexions, d'éclairages indirects... Tout ça est simulé par des "bricolages" consistant à précalculer les résultats de ces phénomènes dans une texture puis à plaquer cette texture lors du véritable rendu. Ca marche pas trop mal parcequ'on fait du statique et on précalcule, et/ou on détourne le pipeline de rendu pour profter de sa rapidité quand c'est possible (rastérisation depuis le point de vue des soruces lumineuse pour les ombres portées, rastérisation depuis un objet pour les réflexions) mais ça reste limité.
Les réflexions par exemple, c'est facile de faire un miroir ou une flaque d'eau, juste une passe de plus. Maintenant si tu veux t'amuser à calculer les reflets de la carosserie d'une voiture comme ça, tu vas exploser ton temps de rendu. Et si tu as plusieurs surfaces réflexives dans ta scène, il va falloir déterminer un ordre de rendu pour chacune en fonction du trajet de la lumière... donc en calculant un ray-tracing.
Bref on se complique sacrément la vie alors que le raytracing gère implicitement tout ces phénomènes avec une précision maximale. On a fait rentrer au chausse-pied un maximum de choses dans le pipeline de rendu qui s'est imposé comme standard parceque ça tournait relativement vite sur les cartes graphiques faites pour ça, mais à un moment il faut bien arrêter de vouloir faire entrer à tout prix des mécanismes inefficaces dans un archi de base très efficace (ça pourrait s'appliquer au deep learning ou au quantique d'ailleurs tiens ).
).
My bad j'ai répondu trop vite, effectivement c'était pour les questions de bruit. Après les problèmes de "clignotement" en mouvement on les aura quel que soit le type de rendu, dès lors où on aura un sous-échantillonnement important dû à la projection dans l'espace caméra. C'est comme l'aliasing, la seule solution sans perte de qualité c'est d'augmenter la résolution. Envoyé par Nilsou
Bon après j'ai peut-être un train de retard, je n'ai plus suivi les évolutions technique en détail depuis un gros paquet d'années... Envoyé par Nilsou
Mais le problème des shaders c'est leur limite d'application : un vertex shader ne va voir qu'un unique vertex lors de son application. De même un pixel shader ne verra qu'un unique pixel.
Or si je veux calculer le trajet d'un rayon correspondant à un pixel donné, j'ai bien besoin d'accéder à tous les éléments géométriques de la scène.
Du coup si on reste dans le cadre du pipelin de rendu et des shaders on bricole. Les pixels shaders ont accès aux textures, donc on va encoder les coordonnées des sommets à la place des valeurs de couleur dans un texture. Puis comme on doit savoir comment sont construites les surfaces avec ces sommets, on va encoder les n° de sommets correspondant à chaque triangle dans une autre texture.
Après pour lancer ce shader, on va faire le rendu d'un beau rectangle. Chaque pixel du rectangle va donc lancer le shader qui calculera une intersection avec le premier triangle du maillage. Puis on va à nouveau rendre le rectangle pour que le shader calcule pour chaque pixel l'intersection avec le second rectangle. Et ainsi de suite jusqu'à ce que chaque pixel ait trouvé une intersection. Et je passe sur l'algo global au-dessus (traversée de grille pour optimiser le nombre de calculs, lancement des rayons secondaires, etc...).
Du coup de nos jours on a de jolis moyens modernes pour utiliser les unités du GPU sans se taper les contraintes d'un pipeline de rendu. Genre cuda, OpenACC... Envoyé par Nilsou
Après bien au contraire l'algo est du genre très massivement parallèle. Pour chaque pixel de l'image à rendre on va lancer un rayon primaire. Le calcul de chaque rayon primaire est totalement indépendant des autres. APrès pour les rayons secondaire on va avoir un peu de synchronisation vu qu'il faudra attendre le résultat du calcul es tous les rayons secondaires d'un rayon primaire pour calculer sa valeur finale (et récursivement le cas échéant...). Mais ces rayons secondaires sont indépendants entre eux et indépendants des rayons secondaires issus d'autres rayons primaires.
C'est bien plus parallèle que la rastérisation d'ailleurs : le calcul de la couleur et la projection pour chaque vertex est certes indépendant, mais pour la rastérisation en elle-même des triangles une fois les sommets projetés dans l'espace caméra, tout se passe dans un unique buffer de rendu, donc une race condition pas piquée des vers et à cette étape c'est chaque triangle à son tour..."Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
17/08/2018, 15h48 #7Tyranaus0r
- Ville
- Une chrysalide
Ok, merci pour tes réponses, je saisi un peu mieux.
Ce que je ne saisi toujours pas c'est comment les fabricants de cartes graphiques, qui produisent depuis des lustres des GPU qui sont censé être des unités ultra-spécialisées pour le pipeline de rendu classique de la rasterization, vont pouvoir proposer des cartes à la fois performante pour le lancer de rayon et à la fois pour la rasterization ...
Je me rends bien compte qu'il est possible de bidouiller en ajoutant des unités de calculs physiques spécialisé en lancer de rayons, mais on double le prix ou presque dans ce cas ... avec, selon l'appli, uniquement une moitié de carte qui sera utilisé
Ou l'architecture physique d'une CG est-elle plus généraliste que je ne le pense ? (je n'ai jamais étudié le sujet mais de mémoire il y avais tout de même une séparation matériel qui existait vis à vis des différentes étapes du pipeline)
-
17/08/2018, 15h50 #8*X86 ADV*
- Ville
- Vence
Il y a quelques papiers et la these d'Ingo Wald qui expliquent comme creer des paquets pour augmenter la coherence (ou un truc du genre, j'y connais rien). Ce gars a ete embauche par Intel par la suite. Et je viens de voir qu'il est chez... directeur RT chez NVIDIA maintenant

-
17/08/2018, 16h07 #9*X86 ADV*
La simple existence du GPGPU montre que ce n'est plus aussi "ulta-spécialisé" qu'avant. Le RT sur GPU n'est pas nouveau (nVidia propose même une API, OptiX, depuis presque 10 ans - vidéo), par contre avoir un truc de qualité et très performant, c'est effectivement une autre histoire. Envoyé par Nilsou
D'un point de vue hardware, ils ont opté pour la solution des unités dédiées dont voici la répartition :

-
17/08/2018, 17h45 #10Tyranaus0r
- Ville
- faquin !
Il y a 10 ans c'était sans doute encore vrai, mais depuis l'introduction du modèle cuda le GPGPU n'est plus un hack de l'archi dédiée au rendu mais vraiment à la base de l'architecture. Envoyé par Nilsou
On n'a plus d'unités de vertex et pixel shaders, on a des "cores" plus généralises qui peuvent effecteur les deux types de calculs (et sans doute d'autres étapes du pipeline je présume). Il doit peut-être rester des unités spécialisées pour l'étape de rastérisation en elle-même (le remplissage des triangles dans le plan de rendu) qui me semble très spécifique.
Je spécule un peu, mais j'ai quand même l'impression qu'on n'est plus tellement dans la course au triangle ces dernières années, et on met beaucoup plus l'accent sur les effets de rendu/post-processing. A ce niveau, l'exécution des shaders avec beaucoup de souplesse et de performance me semble prépondérante sur le fait de pouvoir débiter du triangle brut.
Après l'archi reste toujours très optimisée pour le rendu hein. Même si les coeurs de GPU sont maintenant capables de faire presque autant de choses qu'un coeur de CPU, ils sont trèèès loin d'être aussi efficaces dans toutes les situations. Ils restent taillés pour faire des calculs uniformes sur des grands jeux de données, un algo irrégulier et/ou avec plein de dépendances sur GPU c'est vite la cata à moins de transformer l'algo... quand c'est possible. Exemple que j'ai vu dans le genre : une thèse d'il y a qq années sur le calcul de simu de CFD sur maillages non-structurés. La solution mise en place : sur-échantillonner le maillage pour obtenir un maillage structuré qui rentre bien dans le GPU. Du coup on se retrouve à faire beaucoup plus de calcul, mais avec beaucoup² de puissance de calcul en plus ça reste intéressant. Mais au passage on casse complètement lintérêt du maillage non-structuré qui permet d'avoir des grosses mailles là où on n'a pas besoin de beaucoup de précision et des petites mailles là où les phénomènes importants se passent.
Tldr : appliquer un même shader sur des millions de vertex ou pixels différents, ça reste parfaitement adapté à un GPU actuel.
"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
18/08/2018, 07h57 #11*X86 ADV*
- Ville
- Vence
https://forum.beyond3d.com/posts/2039923/
The RT core essentially adds a dedicated pipeline (ASIC) to the SM to calculate the ray and triangle intersection. It can access the BVH and configure some L0 buffers to reduce the delay of BVH and triangle data access. The request is made by SM. The instruction is issued, and the result is returned to the SM's local register. The interleaved instruction and other arithmetic or memory io instructions can be concurrent. Because it is an ASIC-specific circuit logic, performance/mm2 can be increased by an order of magnitude compared to the use of shader code for intersection calculation.
-
18/08/2018, 21h46 #12Tyranaus0r
- Ville
- Une chrysalide
Le soucis, c'est que comme tu l'a mentionné (et Foudge et newbie06 de même), à l'évidence ils ont décidé de dédier une partie de l'architecture matérielle au RT. C'est donc qu'ils butent sur un soucis qui le nécessite. Ne risque donc t-on pas de se taper le soucis que, justement, la généralisation des cœurs GPU (passage à un paradigme RISC j'imagine) tente d'éviter : des unités sur-spécialisées qui ne seraient utilisé qu'une toute petite partie du temps avec le reste du GPU en dormance. Envoyé par Lazyjoe
Du point de vue utilisateur c'est la cata après en terme de prix (et donc de viabilité du procédé)... non ? Et ça rends la crédibilité du procédé difficile à saisir à long terme pour le grand public ... la nécessité d'avoir un GPU rétrocompatible risque de tuer les tentatives de ne faire qu'un GPU ultra-spécialisé en ray-tracing, et la nécessité d'avoir un GPU abordable risque de tuer toute tentative d’intégrer des unités spécialisées suffisamment performante à coté d'un GPU dédié (à prix abordable) ... non ?
L'article de CPC sur ce point (avec des prédiction comme "du raytracing partout en 2020") me semblait un peu optimiste au vu des difficultés ...
Tient par exemple, est-il possible de mélanger le lancer de rayons avec une rasterization standard (l'un faisant un truc, l'autre un autre) et de le combiner sur le même jeu ? J'ai l'impression que c'est un poil complexe ... (ou alors en virant toute l'étape "enlightment" de la rasterization ? )
J'ai déjà vu pas mal ce genre de solution également dans d'autres domaines (nous on rajoute des neurones fictif ou des liens synaptique fictifs, ce qui est équivalent) Envoyé par Lazyjoe
Et effectivement, ce n'est pas la panacée ...
Dernière modification par Nilsou ; 18/08/2018 à 21h56.
-
18/08/2018, 22h42 #13*X86 ADV*

On vit à l'époque du dark silicon : on sait faire des puces à 10 milliards de transistors avec des horloges à plusieurs gigahertz sans souci, mais on ne peut pas se permettre d'en faire basculer plus de quelques millions à chaque cycle sans que ça crame. Un processeur, c'est quelques îlots de logique dans un océan de mémoire cache. Ça va totalement dans le sens de l'histoire de mettre côte à côte des unités spécialisées pour différentes tâches spécifiques. Individuellement, elles consomment moins que le matériel générique, et tu peux les éteindre quand tu ne les utilise pas. Envoyé par Nilsou
Maintenant, le dessin posté par Foudge n'est évidemment pas à l'échelle ! Si on en croit le lien de Newbie, ce n'est jamais que quelques unités de calcul et un petit cache en plus à l'intérieur des cœurs de calcul généraliste.
Je suppose que le plus gros morceau reste toujours la partie logicielle, ça fait effectivement 10 ans que l'équipe Finlandaise de Nvidia travaille sur OptiX, et ils présentent des trucs et écrivent des brevets régulièrement.
Faudra voir comment Nvidia expose ses nouvelles instructions, mais a priori oui, c'est même sûrement l'application principale envisagée dans un premier temps.Tient par exemple, est-il possible de mélanger le lancer de rayons avec une rasterization standard (l'un faisant un truc, l'autre un autre) et de le combiner sur le même jeu ? J'ai l'impression que c'est un poil complexe ... (ou alors en virant toute l'étape "enlightment" de la rasterization ? )
-
18/08/2018, 23h43 #14Tyranaus0r
- Ville
- Une chrysalide
Tient je ne savais pas, mais c'est complétement ahurissant de non efficacité non ? Envoyé par Møgluglu
 Je ne parle pas d'un point de vue économique, mais d'un point de vue purement efficacité/scientifique...
Je ne parle pas d'un point de vue économique, mais d'un point de vue purement efficacité/scientifique...
Quand tu dit "que ça crame", le soucis se situe au niveau de la dissipation de chaleur du coups ? Mais qu'en théorie avec le même type d'archi on pourrait avoir bien plus de transistors efficaces si on avait une dissipation efficace ? Ou alors c'est carrément due au type d'architecture ... ?
Mais si ce que tu dit est juste, pourquoi avoir tout focalisé sur le RISC a l'époque pour maximiser l'utilisation des unités de calculs, pour ensuite faire machine arrière avec des unités de calcul presque jamais exploités en temps
- - - Mise à jour - - -
Hum, OK, mais dans tout les cas la partie RT devra gérer tout les phénomènes d’éclairage (couteux), elle ne pourra pas partager la gestion de l'eclairage... ça risque d’être un peu couteux si toutes sa partie calcul n'est que constituée de petite unité spécialisées décentralises ... je vois mal comment ça pourra tourner de façon convenable sur de grands environnement avec ce type de limitation ... Envoyé par Møgluglu
-
19/08/2018, 01h29 #15Tyranaus0r
- Ville
- faquin !
C'est déjà présent sur les CPU ce phénomène. Genre les derniers skylake xeon, si tu fait faire aux 28 coeurs du calcul SIMD intensif la fréquence baisse énormément. Envoyé par Nilsou
Cfr le quote de newbie06 : les unités RT ne semble savoir faire que calculer une intersection rayon-triangle. C'est l'opération au coeur de l'algo mais il reste encore plein de choses à faire autour qui vont donner du boulot aux coeurs du gpu : générer les rayons, leur faire traverser une structure grossière pour l'optimisation, lire les propriétés des matériaux, lancer les rayons secondaires le cas échéant, combiner les résultats obtenus par leur lancer... Envoyé par Nilsou
"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
19/08/2018, 08h20 #16*X86 ADV*
- Ville
- Vence
Le debat RISC vs CISC est orthogonal a l'utilisation de blocs dedies efficaces. Pense par exemple aux blocs de codage/decodage video ; ils sont presents sur quasiment toutes les puces parce que quelle que soit la puissance de ton CPU, un bloc dedie sera toujours plus efficace (mais moins configurable evidemment). Envoyé par Nilsou
-
19/08/2018, 12h37 #17*X86 ADV*
Dissipation et alimentation, oui. Au début des années 2000, le meme favori des architectes était un paint de ce genre : Envoyé par Nilsou
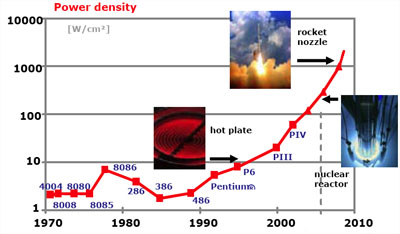
(La source originale doit être une présentation de Pat Gelsinger.)
C'est ça qui a mené à l'abandon de l'archi Netburst et du plan "10 GHz avant 2010" chez Intel, et le passage au multi-cœur.
Parce que le "à l'époque" du RISC c'était les années 1980. Depuis, il y a eu l'ère du superscalaire dans les années 1990, puis celle du multi-cœur, des extensions SIMD et du GPU dans les années 2000. La techno et l'archi ont évolué et le débat RISC/CISC est devenu sans objet. Les cours d'archi de licence s'arrêtent aux années 80, mais l'histoire ne s'est pas arrêtée là, il y a même une petite boîte ou deux qui a continué à faire des processeurs à jeu d'instructions CISC en 1990-2000, je crois qu'ils en ont vendu quelques-uns.Mais si ce que tu dit est juste, pourquoi avoir tout focalisé sur le RISC a l'époque pour maximiser l'utilisation des unités de calculs, pour ensuite faire machine arrière avec des unités de calcul presque jamais exploités en temps
Dans un système de rendu hybride tu utilises justement le RT en complément de la rastérisation pour calculer l'éclairement dans les cas compliqués. Dans un moteur de rendu moderne tu as déjà des centaines d'étapes de rendu, par exemple http://www.adriancourreges.com/blog/...raphics-study/ (voir aussi ses posts sur DOOM 2016 et GTA V). Si on peut faire du lancer de rayon pour pas trop cher, on peut l'utiliser pour certaines de ces étapes, plutôt que faire des rendus sur des cubemaps.Hum, OK, mais dans tout les cas la partie RT devra gérer tout les phénomènes d’éclairage (couteux), elle ne pourra pas partager la gestion de l'eclairage... ça risque d’être un peu couteux si toutes sa partie calcul n'est que constituée de petite unité spécialisées décentralises ... je vois mal comment ça pourra tourner de façon convenable sur de grands environnement avec ce type de limitation ...
-
19/08/2018, 14h43 #18CPC Hardware
je suis pas expert du ray-tracing, mais par contre, sur le reste, on va pas vers un monde avec des unités spécialisées pour chaque tâche. Y a des évolutions intermédiaires avec le passage à une nouvelle techno ou on a deux types d'unités (ou plus) mais à moyen terme, on regroupe le tout. Ici, je suppose qu'on va commencer par séparer le tout (comme on fait pour les trucs liés à l'IA par exemple) avant de tout unifier à terme, comme quand on est passé d'un paradigme de rendu 3D pur à des systèmes capables de calculer comme les actuels. Donc si le rendu en RT devient la norme, ça va peu à peu remplacer les unités classiques, ne serait-ce que parce que si tout le monde utilise ça, les besoins en unités "classiques" diminuera et l'évolution des techno permettra au moins de garder les mêmes perfs en diminuant peu à peu la surface utilisée. Avant éventuellement de l'émuler d'une façon ou d'une autre. Envoyé par Nilsou
- - - Mise à jour - - -
La vidéo, c'est quand même particulier. Techniquement, je doute pas une seconde qu'utiliser les fonctions de calcul des cartes modernes permettrait de faire mieux que les encodeurs/décodeurs dédiés, mais c'est pas ce qu'on recherche. Envoyé par newbie06
Dans la majorité des usages, on doit pouvoir décoder/encoder en temps réel, éventuellement un peu plus vite pour ceux qui font du montage, mais pour l'énorme majorité des usages, on n'a pas besoin de perfs élevées. Et si possible, on doit le faire en consommant peu. C'est plus logique d'un point de vue économique/pratique de faire une partie dédiée dans la puce que de le faire en calcul sur GPU (ou CPU). Et ça permet d'avoir les mêmes capacités partout, en plus.
-
19/08/2018, 15h38 #19*X86 ADV*
- Ville
- Vence
Quand je parle d'efficacite, je pense surtout en terme d'efficacite energetique. Et la tu peux retourner le probleme comme tu veux, un bloc specialise sera toujours plus efficace... jusqu'a ce que sorte une nouvelle norme non supportee Envoyé par Dandu
-
19/08/2018, 22h40 #20Tyranaus0r
- Ville
- Une chrysalide
C'est sans doute logique pour vendre de petites unités spécialisées (pour le décodage sur des plateforme familiale, sur des téloches etc...) mais est-ce logique de le mettre à coté de GPU de joueur ? Hormis par habitude/flemme/facilité d'emploi de la puce dédié produites en masse. Envoyé par Dandu
Sauf qu'il a fallut le produire ton machin. Il est évident que si tu ne pond que des unités sur-spécialisés et que tu assemble le tout sur une plateforme qui demandent à réaliser des milliers de fonctions, pouf, tu doit fondre 100 fois plus de puces ... va falloir que tu fasse tourner longtemps ton bazar pour compenser l’énergie que tu a dépensé pour le créer ... Envoyé par newbie06
A la base les CPU et GPU avaient été conçu pour éviter ce soucis quand même ... on en reviens à défendre ce paradigme parce que les prix de la fabrication de puces sont aux plus bas (état de grâce déjà bien chamboulé dans certains domaine) mais en soit c'est un paradigme qui m'apparait quand même douteux à terme ...
Oui pardon, par RISC j'ai fait un abus de langage, je ne parlais pas forcement des instructions, mais plutôt du paradigme général, même matériel, qui a aboutit à l'intégration de carte spécialisé dans une unité généraliste (CPU/GPU) capable d'utiliser des cœurs généraux pour répondre aux instructions. Envoyé par Møgluglu
Je veut bien d'autres exemple, parce que l'emploi qu'il en décrit est vraiment tout petit petit. Pas certains que ce soit un argument suffisant pour faire une grosse bifurcation technologique ... Moi jusqu'ici j'avais l'impression que l'argument de vente du Ray-tracing c'est son éclairage "crédible", si on peut dire. Pas juste une simple amélioration des réflexions ... En tant que changement de paradigme pour l’éclairage complet ça se tient, mais en tant que simple coups de pousse pour les jeux de lumière sur objets réfléchissant ... bah ça se tient quand même beaucoup moins, amha... surtout que ton coups de pousse ne permet pas de s'affranchir du besoin d'une rasterization efficace en parallèle... donc autant pour le transfert technologique que Dandu cite (voir plus bas) Envoyé par Møgluglu
C'est là que tout un pan de l'hypothèse me parait douteux. Ce que tu décris de passage d'une techno à une autre marche bien quand on peut aisément jeter l'ancienne techno (parce que ses consommables ont une durée de vie, par exemple) alors que quand on est sur des JV (et plus généralement sur les PC) c'est le bordel, tout les JV de la vie fonctionnent selon un paradigme, bon courage pour les jeter à la poubelle (et beaucoup d'entre eux ne "périment" pas)... surtout que tout a tenu jusqu'ici par la sacrosainte rétro-compatibilité ... Envoyé par Dandu
Sauf que de ce qu'on en vois ils semblent galérer énormément à adapter les algos de raytracing au calcul déjà bien généraliste des cœurs de CG.
Alors certes la solution de mettre quelques unités spécialisées donnera un résultat acceptable (sur une carte mastodonte difficile d’accès au public) mais n'est-ce pas une façon de remettre à plus tard le soucis... avec pour le moment aucune véritable solution élégantes ... ?
Alors si les deux techs étaient aisément mélangeable je dis pas (l'une ferais un bout, l'autre un autre bout), mais à l'évidence ça semble être difficilement le cas, le ray-tracing étant capable de faire 100% du rendu, il rends obsolète l'autre tech ... et les apports qu'il est capable de donner à la rasterization comme "aide" sont pas vraiment convaincant seuls... (les surfaces réfléchissantes)Dernière modification par Nilsou ; 19/08/2018 à 22h59.
-
19/08/2018, 23h23 #21Tyranaus0r
- Ville
- faquin !
En même temps je suis beaucoup plus dubitatif sur les tensor cores pour le grand public.
Il faudra voir la disponibilité réelle dans les cartes grand publique... Je pense qu'ils vont surtout cibler dans un premier temps les pros du rendu (avoir la possibilité de bosser sur des pré-rendu raytracés en temps réel ou presque ça devrait intéresser du monde je pense).
Pour l'instant ils annoncent des perfs pas forcément très utiles (c'est quoi de "gigarays par seconde" exactement ) si ça tombe ces unités occupent 5% de la carte à tout casser.
Ca me fait penser aux cartes pour accélérer les calculs physiques du début des années 2000 tiens. D'ailleurs des circuits capables de calculer des intersectiosn, ça peut être pas mal pour accélérer le calcul de collisions aussi.
"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
20/08/2018, 10h03 #22*X86 ADV*
- Ville
- Vence
Tu sais combien coute un jeu de masques ? Bien plus que le cout de developpement d'un bloc de codage/decodage. Et en plus ca ne coute rien en surface, alors autant le faire, ca evite de creer des dizaines de masques. Envoyé par Nilsou
Le cout de dev d'un bloc moderement performant est infiniment inferieur a celui qu'il faut mettre pour rendre un CPU/GPU assez performant et generique pour accomplir la meme tache.Sauf qu'il a fallut le produire ton machin. Il est évident que si tu ne pond que des unités sur-spécialisés et que tu assemble le tout sur une plateforme qui demandent à réaliser des milliers de fonctions, pouf, tu doit fondre 100 fois plus de puces ... va falloir que tu fasse tourner longtemps ton bazar pour compenser l’énergie que tu a dépensé pour le créer ...
A la base les CPU et GPU avaient été conçu pour éviter ce soucis quand même ... on en reviens à défendre ce paradigme parce que les prix de la fabrication de puces sont aux plus bas (état de grâce déjà bien chamboulé dans certains domaine) mais en soit c'est un paradigme qui m'apparait quand même douteux à terme ...
Et si tu crois qu'on peut faire evoluer la performance des CPU/GPU programmables sans limite, tu te leurres completement. Du coup, meme si on oublie l'argument de l'efficacite energetique celui de la performance brute entre en ligne de compte, et celui du cout de developpement est tres fortement en defaveur du CPU/GPU. Bon courage pour encoder du VP9 avec uniquement du SW.
Cet argument me fait penser a Larrabee : pourquoi faire un GPU quand on sait faire des CPU performants, apres tout on peut programmer un CPU pour faire tout ce qu'un GPU fait. Gros succes, n'est-ce pas ?Oui pardon, par RISC j'ai fait un abus de langage, je ne parlais pas forcement des instructions, mais plutôt du paradigme général, même matériel, qui a aboutit à l'intégration de carte spécialisé dans une unité généraliste (CPU/GPU) capable d'utiliser des cœurs généraux pour répondre aux instructions.
Je ne defends pas a tout prix les blocs specialises, je suis bien au contraire un farouche partisan de l'approche CPU avec des unites SIMD/vectorielles bien massives. Mais force est de constater que les blocs specialises offrent de tels avantages qu'il est impossible de s'en passer.
-
20/08/2018, 10h43 #23*X86 ADV*
Des GPU de joueurs pas tout à fait. Jusqu'ici on avait d'un côté un énorme GPU très bon en GPGPU double précision et de l'autre un GPU de taille plus raisonnable à destination exclusive des joueurs et présentant un excellent rapport perf/transistors/W/prix mais mauvais en double précision. Envoyé par Nilsou
Là au final on ne fait qu'ajouter de la spécialisation à un GPU orienté GPGPU et non gaming.
Pourquoi 100 puces ? Aujourd'hui on est capable de produire une unique puces composées de dizaines d'unités spécialisées différentes (en plus de grosses unités génériques et de plein de caches). Et ça a du sens de faire ça à destination d'appareils basses consommation multifonctions. Envoyé par Nilsou
Et encore, Intel a quand même dû ajouter des unités spécialisées (texture). Envoyé par newbie06
-
20/08/2018, 10h57 #24*X86 ADV*
En fait l'enjeu n'est pas juste de spécialiser pour le plaisir de spécialiser. C'est plus d'amortir le surcoût du modèle de Von Neumann en augmentant la granularité des opérations.
Idéalement, on aimerait définir un jeu d'instructions avec des opérations les plus génériques possibles, mais qui font le plus de travail utile possible. C'est l'idée derrière les unités virgule flottante, les unités SIMD, les FMA, les diviseurs (le Power s'en passait), les multiplieurs entiers (l'Itanium s'en passait), les instructions de calcul d'adresse plus ou moins à la con genre shift+add+add ou pre/post-incrément, les multiplieurs sans retenue, etc.
Si on veut aller plus loin, on se retrouve obligé de spécialiser pour des algos précis, mais ça reste des opérations contrôlés par du software, pas des ASIC.
L'approche de Nvidia a l'air plutôt raisonnable : les Tensor Cores sont des instructions qui calculent des petits produits de matrices de taille fixe, avec les entrées et les sorties dans les registres, c'est RISCasher. Les RT cores semblent être des unités de calcul d'intersection entre une droite et un ensemble de triangles, une opération générique de base en rendu 3D. Elles accèdent visiblement à la mémoire avec un cache dédié, mais le passage cité dit clairement que c'est une instruction dans le SM qui renvoie son résultat dans les registres. C'est largement plus générique que les instructions AES des CPU Intel, par exemple.
-
20/08/2018, 22h27 #25Tyranaus0r
- Ville
- Une chrysalide
Je n'avais pas fait le liens, mais du coups c'est exactement ça Envoyé par Lazyjoe
-
22/08/2018, 16h31 #26CPC Hardware
Dans le contexte classique évidemment, vu que 99% des gens ont pas besoin de perfs élevées et d'une bonne efficacité énergétique. Et on peut faire ça pas cher. Après, pour ceux qui veulent un truc qui encode vite, un calcul sur GPU haut de gamme ou un encodeur de ouf, lequel est le plus intéressant ? Tant d'un point de vue énergétique que du coût, je parierais pas sur l'encodeur dédié. Mais bon, je sais même pas si des gens font des encodeurs dédiés très rapides, en fait. Envoyé par newbie06
-
22/08/2018, 16h51 #27*X86 ADV*
- Ville
- Vence
Tous les SoC haut de gamme ont des encodeurs materiel parce que tu n'as simplement pas assez de perf sinon. Envoyé par Dandu
-
25/08/2018, 00h33 #28Tyranaus0r
- Ville
- Une chrysalide
Rappelle moi déjà pourquoi on ne sait pas exploiter l'archi GPU existante pour faire des petits produits de matrices de taille fixe ? Je croyais que le GPU ne faisait que ça, en gros ... Envoyé par Møgluglu
Mais ça fait longtemps que j'ai eu les cours sur le sujet (9 ans ?) ma mémoire est flou sur le sujet ...
Ou alors c'est juste que le nombre de petit produit matricielle est affreux sur le raytracing donc autant en faire tout pleins en parallèle ?
Ça c'est cool si c'est programmable par contre, je vois bien d'autres utilisation de ces tensors core que le raytracing du coups
-
25/08/2018, 10h40 #29Tyranaus0r
- Ville
- faquin !
On sait le faire, mais ça reste beaucoup moins efficace qu'une unité hardware spécialisée. Envoyé par Nilsou
cfr https://devblogs.nvidia.com/wp-conte...8207263673.png
Un tensor core est capable de faire un multiplication de matrice 4x4 en un cycle d'horloge. Donc 64 flops. En introduisant 1/8ème de tensor cores (8 par SM à côté de 64coeurs cuda) les perfs sur cette opération en particulier sont multipliées par ~8, difficile de faire plus rentable.
Bon après il y a une petite astuce, cette multiplication ne se fait que sur des données en demi-precision. Ca limite un peu l'utilité dans le cas général.
Pour l'étape de projection dans la rastérisation effectivement, mais pas dans le reste du pipeline. A voir avec un spécialiste quelle proportion ça occupe de nos jours mais pas tant que ça je pense (ça fait combien de temps qu'on ne nous vend plus des cartes "capables d'un débit de plein de milliard de triangles tavu !" ? Envoyé par Nilsou
)
Les coeurs cuda ce sont des unités en virgule flottante généralistes en soi.
Ben heuuuu y en a pas en raytracing Envoyé par Nilsou
 "Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
25/08/2018, 11h51 #30*X86 ADV*
Les entrées-sorties. Envoyé par Nilsou
Avec des unités conventionnelles tu décomposes ton produit de matrice en produits scalaires, et tu calcules chaque produit scalaire avec une succession d'instructions FMA : c_ij = a_ik × b_kj + c_ij. Pour un produit de deux matrices n×n, ça te fait 3n^3 nombres à lire et n^3 nombres à écrire dans les registres, pour faire n^3 FMA.
Avec une unité de produit de matrice dédiée, mettons 16×16, tu décomposes ta matrices en blocs. Pour chaque bloc, tu calcules le sous-produit C_ij = A_jk × B_kj + C_ij, dans lequel il y a 3×16^2 nombres à lire et 16^2 à écrire pour 16^3 FMA. Tu peux alors faire 20 fois plus de calculs pour une bande passante avec les registres donnée.
Ce n'est pas utilisé quand on travaille en double ou même en simple précision, car les registres SIMD ne sont pas assez larges pour permettre des sous-matrices de taille suffisante pour que le gain soit suffisant pour justifier d'ajouter des instructions (au mieux tu arrives à 4×4). Mais plus tu travailles sur des mots petits, plus tu gagnes. À l'extrême, le Cray 1 avait une instruction de produit de matrices de bits 64×64 (quelques processeurs modernes aussi).
Je te rassure, il y a 9 ans tout le monde était déjà convaincu qu'il fallait calculer en simple ou double, quasiment personne ne parlait encore de deep learning sur GPU, et la question ne se posait pas.")
Pour être clair : les tensor cores n'ont pas de rapport avec le lancer de rayon, c'est prévu pour les réseaux de neurones convolutifs. Je le mentionnais juste comme unité spécialisée en général, pardon pour le hors sujet.


 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non