
Les architectures dédiées au deep learning sont décidément à la mode. Quelques annonces récemment :
- Google fait un retour d'expérience sur son Tensor Processing Unit version 1, qui sera présenté à ISCA 2017 :
https://www.arxiv.org/abs/1704.04760
Le TPU 1 est un accélérateur de produit de matrice en virgule fixe 8 bits dédié à l'inférence uniquement. Pour l'apprentissage Google utilise des GPU comme tout le monde.
Et introduit la version 2 du TPU dans la foulée :
https://www.nextplatform.com/2017/05...ning-clusters/
Cette fois on a du calcul flottant (probablement FP16) pour faire l'apprentissage en plus de l'inférence. Le TPU 2 se place donc en concurrent des GPU.
- Chez Nvidia, le GPU Volta GV100 intègrera des Tensor Cores :
https://devblogs.nvidia.com/parallel.../inside-volta/
Ce sont des unités dédiées aux produits de matrices en FP16.
Si le serveur DGX-1 avec GV100 à 150K$ vous semble trop gros et trop bruyant, Nvidia propose désormais la DGX station pour poser sur son bureau, à seulement 69K$.
- Chez Intel, le prochain Xeon Phi Knight Mill visera aussi le marché du deep learning, ce qui sous-entend certainement des unités dédiées, mais pas de détail pour l'instant.
On en saura plus sur tout ces bidules au prochain Hot Chips en août : les 3 sont au programme.

Affichage des résultats 1 à 28 sur 28
-
23/05/2017, 11h10 #1*X86 ADV*


-
24/05/2017, 21h54 #2*X86 ADV*

- Ville
- Laincanard
Concurrencer les GPUs, c'est dégueulasse !

En vrai, c'est pas si étonnant, et de toute façon Nvidia a déjà bien revu la segmentation de sa gamme et séparant un peu plus les GeForce des Tesla. On est loin de l'époque où les GeForce étaient des bêtes en double précision, et où il était inutile d'acheter des Tesla hors de prix du moment que l'ECC et les très grosses quantités de VRAM n'étaient pas nécessaires.
Ce sont les très petites entreprises (les startups quoi) qui en pâtissent, je pense, les joueurs s'en cognent en théorie.
Du coup, pourquoi ne pas avoir des cartes dédiées au deep learning ? Avec des DLPU (deep learning processing unit) ? Ou des MLPU (machine learning processing unit) ?
Si Ageia s'était vautré, c'était parce qu'ils essayaient de vendre des cartes à prix d'or pour ajouter quelques effets de physique sympas mais totalement optionnels dans quelques jeux.
Et en dehors des quelques Kévins fortunés, la masse des joueurs c'est le milieu de gamme avec des cartes au rapport perfs/prix le plus intéressant possible, ça n'intéressait donc pas grand monde.
Là aussi on parle de vendre des cartes spécifiques pour un usage précis, ça se ressemble, mais à des entreprises, c'est pas pareil.
Et pas pour du cosmétique en jeu, mais bien des traitements IA / machine learning / deep learning qui ont le vent bien en poupe en ce moment.
Ce serait pas étonnant si, en plus de commencer à équiper ses Tesla avec de telles unités, Nvidia finissait un jour par sortir des GPUs et des cartes spécialement pour ce milieu, bourrées d'unités comme ça et complètement moisies en rendu 3D classique.
-
24/05/2017, 22h21 #3*X86 ADV*
Et on appellera ça le Tesla Psi.
Blague à part, c'est peu probable, étant donné qu'ils devront garder tout ce qui fait la valeur ajoutée du GPU : les unités de calcul généralistes, le système mémoire, le scheduler de threads, CUDA, le compilateur, le driver... Les unités réellement dédiées au rendu 3D qui restent, c'est pas grand-chose au final.
Mais surtout, ils sont encore plus malades que ça. La nouvelle lubie de Jensen, c'est de faire de la réalité virtuelle... pour les bébés robots.
D'où l'intérêt des unités de rendu graphique dans les GPU pour le deep learning.
J'hésite encore entre le dégoût et la fascination.
-
24/05/2017, 23h05 #4*X86 ADV*
- Ville
- Laincanard
Ben, je serais pas aussi catégorique.
Ils peuvent très bien garder toute cette valeur ajoutée que tu mentionnes, mais si leur Volta 100 fonctionne bien, se mettre à sortir des cartes de plus en plus costaudes au niveau des tensor cores et de plus en plus rachitiques niveau rasterization et CUDA cores.
L'avenir nous le dira.
Ce qui est sûr c'est que, sur des GPUs "classiques" ou "spécialisés", Nvidia n'est pas prêt d'abandonner le deap learning...
-
30/11/2017, 17h17 #5*X86 ADV*
Les nouvelles extensions pour le machine learning de l'extension AVX-512 sont documentées : https://software.intel.com/sites/def...-reference.pdf
Ça comprend les nouvelles instructions de produit scalaire dans Ice Lake, AVX512_VNNI. Par exemple :
Mais au moins, depuis l'annulation de Knights Hill, on a échappé au pire : on aurait pu avoir aussi l'extension AVX512_4VNNIWVPDPWSSDS zmm1{k1}{z}, zmm2, zmm3/m512/m32bcst
Multiply the word integers in zmm2 by the word integers in zmm3/m512, add adjacent doubleword results with signed saturation, and store in zmm1 under writemask k1.
VP4DPWSSDS zmm1{k1}{z}, zmm2+3, m128
Multiply signed words from source register block indicated by zmm2 by signed words from m128 and accumulate the resulting dword results with signed saturation in zmm1.
This instruction computes 4 sequential register source-block dot-products of two signed word operands with doubleword accumulation and signed saturation. The memory operand is sequentially selected in each of the four steps.
In the above box, the notation of “+3” is used to denote that the instruction accesses 4 source registers based on that operand; sources are consecutive, start in a multiple of 4 boundary, and contain the encoded register operand.
-
30/11/2017, 17h31 #6Tyranaus0r


- Ville
- faquin !

Faut faire un paint là !"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
Envoyé par Sidus Preclarum

-
30/11/2017, 17h35 #7*X86 ADV*
- Ville
- Laincanard
Quoi, t'es raciste envers les produits scalaires ?

-
13/05/2018, 20h39 #8*X86 ADV*
Infos et photos sur le TPU 3.0 de Google :
https://www.nextplatform.com/2018/05...i-coprocessor/
Ça semble grosso-modo pareil que le v2 en plus gros et watercoolé.
Sinon j'avais pas vu les détails du "brain" float avant : c'est un format Binary32 mais avec la mantisse réduite à 7 bits. Soit des nombres à 2 chiffres décimaux significatifs. J'attends avec impatience les formats avec 0 ou un nombre négatif de bits de mantisse.
-
13/05/2018, 22h28 #9*X86 ADV*
- Ville
- Laincanard
Haha t'es vraiment trop bête Envoyé par Møgluglu
 mais ça serait rigolo de tomber sur un papier, même fake, présenté comme une vraie thèse ou un vrai rapport et qui parle de ça sérieusement
mais ça serait rigolo de tomber sur un papier, même fake, présenté comme une vraie thèse ou un vrai rapport et qui parle de ça sérieusement
-
14/05/2018, 10h56 #10Tyranaus0r
- Ville
- faquin !
Ils parlent de bfloat16 dans l'article, avec 7 bits de mantisse et 8 d'exposant. L'intérêt semblant être dans le range qui est identique aux float32 classique (8 bits d'exposant) donc conversions et opérations mélangeant les deux types beaucoup plus rapides contrairement au float16. Envoyé par Møgluglu
Effectivement on se demande encore pourquoi utiliser des float à ce niveau.
"Avant, j'étais dyslexique, masi aujorudh'ui je vasi meiux." Envoyé par Sidus Preclarum
-
14/05/2018, 11h30 #11*X86 ADV*
Envoyé par taronyu26

Spoiler Alert!
C'est la question que je me pose. Pour faire des produits scalaires avec des précisions équivalentes à du flottant avec moins de 10 bits de mantisse, il y a des solutions qui devraient être plus avantageuses en surface et conso que le flottant. Envoyé par Lazyjoe
C'est probablement pour simplifier les conversions entre formats comme tu dis. (Ou alors c'est parce qu'ils ne connaissent que le flottant et la virgule fixe, et qu'ils ont déjà essayé la virgule fixe dans le TPU 1.)
-
14/05/2018, 15h26 #12*X86 ADV*
- Ville
- Laincanard
Oups. Désolé... Envoyé par Møgluglu

Le flottant est mort ! Vive le flottant !
-
24/05/2018, 16h01 #13Tyranaus0r

- Ville
- Une chrysalide
Moi j'ai quand même une question dans tout ça Mogluglu.
Au labo ou je bosse on n'en finit pas de se demander "POURQUOI", pourquoi donc d'un coups tout le monde se met à fabriquer des accélérateur pour deep-learning, et surtout : ou en est l’intérêt ?
Je m'explique :
-Pour la recherche et les labos l’intérêt est assez évident pour les "petites expés", et encore, la structure de ces accélérateurs empêchera de fait d’expérimenter sur le type de modèle d'apprentissage et l’intérêt restera donc vachement restreint. Mon labo, par exemple, après avoir étudié la chose, a décidé de ne pas tester ces modèles pour le moment. En effet on a déjà moult super-calculateur généraliste, bien suffisamment pour apprendre sur des immense base dans un temps raisonnable tout en changeant ce qu'on veut dans l'expé. Pourquoi on en achèterais alors ?
- Pour le particulier c'est encore plus mystérieux, le deep-learning (et le l'apprentissage en général, deep ou non) ne pose un problème de performance que dans un unique cas : si on veut obtenir un résultat rapide à l'apprentissage sur une très grande base. Mais par définition ces très grandes bases sont construite lentement et le particulier n'a donc accès qu'a celles déjà dispo. Si on imagine un modèle d'apprentissage dans une appli pour un particulier, il sera vraisemblablement livré avec l'apprentissage déjà fait et dans ce cas le deep-learning ne pose aucun soucis de performance à l’exécution. Le seul cas ou ce genre de modèle serait en "apprentissage permanent" serait si le particulier dans l’interaction avec le logiciel donne de nouvelles infos. Mais dans ce cas les nouvelles infos apparaitrait TRÈS LENTEMENT (puisque le particulier n'est pas un poulpe manipulant le logiciel à la vitesse de la lumière) et donc la rectification de l'apprentissage ne se ferait qu'une fois de temps en temps, en tache de fond. La encore le cout calculatoire de l'opération est virtuellement nul.
Question donc, en dehors du vent de la hype, à qui ce hardware peut-il bien s'adresser ?
Parce que moi et mes collègues... on vois po.
-
24/05/2018, 16h39 #14*X86 ADV*
Parce que le cloud.
")
Ceux qui achètent ces machines sont les "hyperscalers", Google, Baidu, Amazon, Microsoft, Yahoo etc. et les fournisseurs de service cloud (plus ou moins les mêmes), qui en mettent plein leurs datacenters. Mais pour un labo ou même une entreprise de taille raisonnable, à moins que tu traites des données vraiment sensibles qui justifient que tu maintienne ta propre infrastructure de calcul, tu n'as pas vraiment de raison d'acheter directement ce genre de hardware. Par contre, ça a totalement du sens de louer des instances dans le cloud quand c'est moins cher que l'amortissement d'un serveur de calcul local.
Pour le particulier, il utilise déjà ces accélérateurs tous les jours sans même faire attention, toujours dans le cloud. Pour la reconnaissance vocale, les recherches sur le web, la classification d'images, l'affichage des pubs et autres suggestions... Pas besoin de se balader avec un datacenter dans la poche quand on en a toujours un à proximité dans l'internet.
Le PC des années 90 que tu achètes pour poser sur ton bureau, c'est fini. On est revenu à un modèle plus proche de celui des années 60-70, où l'ordinateur, il ne t'appartient pas, il occupe un bâtiment fermé, climatisé, surveillé et entretenu par du personnel h24, et tu le partages avec le reste du monde.
-
24/05/2018, 17h01 #15Tyranaus0r
- Ville
- Une chrysalide
Mouuuuaaaaiiiis, ça fait 20 ans que tout les 5 ans ils se répètent la même chose. Mais dans la réalité ça ne perce jamais par la suite. Par exemple, je ne connais AUCUN labo (du moins ceux faisant de l'IA en France ou au japon et que je connais) qui loue un service cloud pour faire ses calculs. 100% d'entre eux préfèrent avoir un super-calculateur à la maison à partager entre labo plutôt que de dépendre d'une boite et d'une location pour faire sa recherche (en grosse boite j'ai bossé à StMicro à Rousset, et c'est pareil). Envoyé par Møgluglu
Quant au PC maison, malgré le même genre d'oracle, les joueurs continuent d'acheter un PC puissant à la maison au lieu de louer Faut croire que les oracles ont déjà fait la preuve de leur échec sur ce sujet. Ne faudrait-il pas les prendre avec des pincettes du coups ?
Bon après si tu bosse dans une boites de cloud je comprends que tu ai besoin d'y croire
Par contre je vois bien, en effet, maintenant que tu le dis, pourquoi les grosse boites comme google et cie ont besoin d'optimiser leur matos pour ces applications, surtout si ils en utilisent un peu partout (reco vocale et cie, moteur de recherche, publicités etc...) . Mais ça fait pas un super marché de la mort. Une fois qu'ils sont équipés ils ne vont pas s'amuser à faire rouler leur matos tout les jours ... (contrairement au particulier) surtout que du coups ils produisent beaucoup pour régler leurs propres problèmes internes ici. Les boites externes n'auront que peu d’intérêt pour ce type de matos.
-
24/05/2018, 17h46 #16*X86 ADV*
C'est pas juste une question d'y croire ou pas, il y a des vrais leviers économiques derrière. Bien sûr que tout le monde préfère conserver son indépendance, encore faut-il avoir les moyens de suivre. Pour reprendre l'exemple de ST Micro, ils auraient aussi bien voulu garder leurs fabs et les maintenir à la pointe s'ils avaient pu. Mais tout le monde n'est pas Intel pour avoir les moyens de maintenir ses propres fabs (et encore, quand on voit la panique post-14nm chez Intel...)
Et pour l'autre exemple, les joueurs PC sont une toute petite minorité des joueurs. Le joueur moyen il joue sur un smartphone avec une connexion 4G, et il peut passer au cloud du jour au lendemain si c'est le truc de l'app à la mode.
Dans le cas du deep learning, l'économie d'échelle de l'organisation en datacenters et le gain en efficacité énergétique des archi spécialisées et vraiment significatif. Si tu n'as pas ça, tu n'es pas compétitif face à tes concurrents qui y ont accès. Accessoirement, en externalisant dans du cloud tu transformes des investissement de capitaux en dépenses opérationnelles, et ça les financiers adorent. (Même dans la recherche publique, hélas.)
-
24/05/2018, 19h20 #17Tyranaus0r
- Ville
- Une chrysalide
Le joueur moyens sur son smartphone n’apprécierais guère de ne pas pouvoir jouer dans les zones non couverte, amha
. En tout cas actuellement.
Quant à ST il ne tourne que ses nouveaux projet vers le fabless, ses usines ne sont pas (du tout) fermé... donc ce n'est pas une boite fabless pour le moment. Et sa décision a été hautement critiqué par pas mal de monde, pour certains cela équivaudra à un suicide à long terme. Donc ...
Ces exemples ne sont donc pas forcement très juste, je trouve.
Pour le moment ça reste de la supposition du coups, j'attends de voir. Dire "il y a des leviers économiques derrière" ne veut rien dire. Qu'ils essaient de faire du "tout cloud" avec des milliard ne garantit en rien leur réussite.
Amha, les boites qui ont besoin de deep learning puissant sont les mêmes que celles qui ont les moyens de maintenir des fermes de calculateur, et c'est ce qu'elles font d'ailleurs. Elles ne voudront pas dépendre de leurs propres concurrents
Quant au gain des archi spécialisés, j'aimerais bien voir un papier comparatif par rapport à un GPU
-
25/05/2018, 09h56 #18Randy 2015

Tu prends l'exemple d'un cas de niche en 2018, l'écrasante majorité de la population a une couverture data satisfaisante en Europe. Pour donner un autre exemple, quand je travaillais avec Airtel (Inde) ou Sinodata (Chine) il y a déjà 7 ans, les gens avec qui j'avais contact m'ont expliqué que dans leurs pays l'accès à Internet se faisait assez peu par du réseau câblé. J'ai eu la même conversation avec un FAI bulgare il y a 2 ans. Envoyé par Nilsou
En fait les opérateurs, ne disposant pas d'un bon réseau cuivre/fibre historique, ont directement fait le saut à la 3G/4G/whatever en réduisant ainsi considérablement leurs coûts d'infrastructure tout en adressant la majorité de la population. C'était en Inde/Chine, il y a 7 ans.
Donc oui, la couverture data est désormais la norme plus que l'exception."La vaseline, c'est un truc que j'utilise systématiquement" - vf1000f24
-
25/05/2018, 21h33 #19Tyranaus0r
- Ville
- Une chrysalide
Je ne sais pas si ça change quelque chose. Il y a un aspect psychologique important au fait de pouvoir ou non accéder à des fonctionnalités sur un périphérique lorsqu'il est hors ligne. Et il ne faut pas confondre la couverture de la population en moyenne et celles des campagnes. Par exemple, quand je prenais le bus en chine, point de réseau 4G entre les destinations. L’activité principales des chinois dans le bus était de jouer (enfin, des jeunes et des nana surtout). Quelque chose me dit que l'appli qui prends le risque de ne pas être dispo quand le réseau est faible (typiquement ce cas) se retrouvera immédiatement délaissé par les utilisateurs... qui en ont besoin précisément dans ce cadre. (cadre qui se maintiendra car les opérateurs ne verront aucun intérêt à déployer dans des zones désertes de populations) Envoyé par Minuteman
Donc oui, tu te retrouve dans un pays ou la majorité de la population est couverte, mais ou aussi, si tu fait le compte, une grande partie subit des coupures sur ses trajets. En moyenne dans la stats de couverture ça ne compte pour rien, mais ça compte beaucoup pour savoir si tu choisira une appli ou non.
Pour les jeux et pour les exemples que vous donnez en general je ne pense donc pas que votre raisonnement soit juste, ou en tout cas, je le trouve très partial et peu étayé. Mais on dérive de conversation car ça n'a que peu de rapport avec l'apprentissage automatisé, tout ceci. Par contre j'admet que les plus grosses applications de l'apprentissage sont externalisé dans des fermes externes. Mais là ou je bloque c'est que ceux qui ont besoin de ces applis (google et consort) sont aussi ceux qui produisent le matos pour résoudre le problème. Résultat des courses : y aura t-il véritablement un marché pour ce genre de matos vu qu'ils vont surtout produire pour leur propre usage. Et je vois mal, par exemple, Nvidia acheter une grosse quantité de matos google pour ses propres fermes...
D'ailleurs n'observe t-on pas qu'ils produisent tous en parallèle leur propre solution depuis ce qui tourne déjà chez eux à la maison ?
-
28/05/2018, 15h42 #20*X86 ADV*
À part Google justement, il y a des boîtes de services qui conçoivent leurs propres accélérateurs ? J'ai l'impression que c'est surtout Nvidia, Intel, Qualcomm, AMD et diverses start-up qui se lancent dans le hardware pour le deep learning... Envoyé par Nilsou
-
30/07/2018, 12h10 #21*X86 ADV*
Encore un accélérateur d'inférence en deep learning pour l'analyse d'image :
https://arxiv.org/pdf/1804.08711
Petite originalité, ce n'est pas de l'électronique, c'est un classificateur entièrement optique formé de lentilles construites par impression 3D. Je suis sûr qu'ils auraient pu mettre le mot quantique dans le titre s'ils avaient voulu.
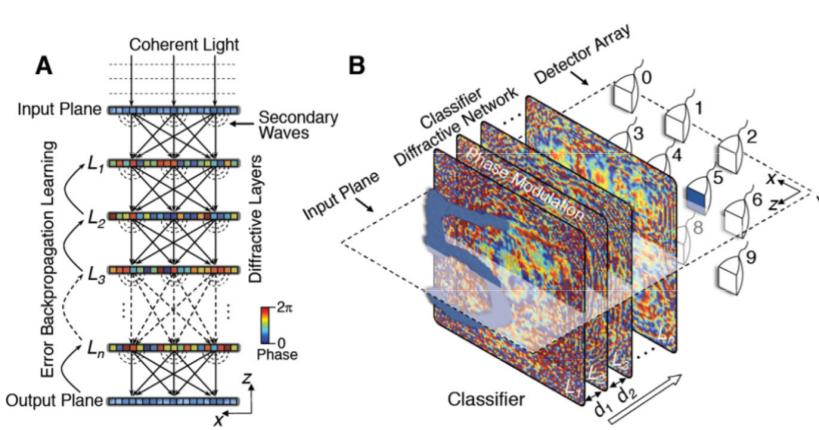
Je reviens, je vais imprimer une paire de lunettes à détecteur de chaton.")

-
30/07/2018, 14h00 #22*X86 ADV*
- Ville
- Laincanard
On n'arrête vraiment pas le progrès
Si tu aboutis à un prototype prometteur, je veux bien en bêta-tester une paire Envoyé par Møgluglu

-
30/07/2018, 15h16 #23*X86 ADV*
Attend la prochaine étape : les lunettes qui implémentent le content-aware fill de Photoshop pour ajouter des chatons là où il en manque.

-
30/07/2018, 15h26 #24*X86 ADV*
- Ville
- Laincanard
Le monde n'est pas prêt

-
31/07/2018, 18h18 #25*X86 ADV*
- Ville
- Vence
n33d Envoyé par Møgluglu

-
31/07/2018, 19h19 #26*X86 ADV*
L'autre exemple du papier, c'est un jeu de lentilles genre objectif d'appareil photo à qui on a appris à projeter des images le plus fidèlement possibles.
Donc plutôt que de concevoir des formes de lentilles soigneusement étudiées pour minimiser la diffraction dans le cas général, on balance les équations dans un algo d'apprentissage et on récupère un objectif avec plein de diffractions internes dont on ne sait pas trop comment il marche, mais qui est entraîné pour fonctionner correctement sur un grand jeu de données.
On voit tout de suite le merveilleux potentiel orwellien de cette invention : on pourrait spécialiser des objectifs pour certains types de sujets avec des performances médiocres sur les autres, ou mieux, apprendre à l'objectif à censurer tout seul ce qu'il voit.
-
31/07/2018, 19h35 #27*X86 ADV*
- Ville
- Laincanard
Bientôt on aura des voitures autonomes sans ABS ni ESP mais à qui on aura appris à faire de la mise en dérive et du freinage dégressif.

-
11/08/2018, 15h17 #28Tyranaus0r
- Ville
- Une chrysalide
Attention à cet article, il a plusieurs soucis je trouve, qui en diminue sacrement l’intérêt.
- Le concept de lentille/suite de lentille spécifiquement conçue pour détecter un motif ou donner tel ou tel comportement par rapport à une entrée n'est pas nouveau du tout. Avant que l’électronique aient atteint le niveau qu'elle a aujourd'hui, ce fut notamment utilisé pour le guidage de missile (le traitement optique et la reconnaissance de la cible étant infiniment plus rapide ainsi. ). Les ingés concevait un peu au pif la lentille, certes, mais par la suite avec le développement de l'informatique ils ont simplement fait en simu une exploration de tout les possibles pour trouver la lentille qui va bien. (Algorithme de recherche génétique ou de recuit simulé). Ce type de guidage/reconnaissance optique est encore utilisé aujourd'hui dans certaines applications ou le temps de reconnaissance est critique.
- L'apprentissage est ici fait en simulation. Cette phrase devient donc partiellement fausse : " [...] avec plein de diffractions internes dont on ne sait pas trop comment il marche, mais qui est entraîné pour fonctionner correctement [...]" car dans le cas d'une simulation on connait 100% des équations impliqués, donc l’intérêt d'un systeme qui apprendrais sur de véritable lentille physique (avec leur défaut, leur irrégularité etc...), intérêt qui serait grand, s'évapore complétement. Ici un simple recuit simulé sur le jeu d'équation, comme on le fait depuis les années 90 aboutirait au même type de résultat. Ce genre de divergence entre réalité et simulation dans un systeme apprenant à notamment été mis en évidence sur des systeme électronique type FPGA apprenant en live sur le FPGA. En simu on obtient une solution bête et méchante, proche de celle qu'on aurait implémenté ou trouvable aisément, et bouffant pas mal de circuit. Hors simu l'apprentissage se met à utiliser des phénomènes d’interférences, de champs magnétique etc... qui était absolument non prévu (ce sont des "défauts" de la plateforme matérielle). Le résultat est plus malin, plus performant etc ... c'est l'avantage principal d'apprendre directement sur une plateforme matérielle. Ici cet avantage s'évanouit. Les propositions en fin d'article pour implémenter un systeme apprenant directement sur la lentille sont très minimale et naïve, je trouve. Si ils concentraient leur taf sur ce point ce serait pourtant bien plus intéressant.
- Le test qu'ils font en pratique n'est guère concluant. Ils font apprendre leur systeme sur un exemple "débutant" qui n'a absolument aucun intérêt (Les distinctions sur des chiffres de 0 à 10 qui sont bien centrés sont trouvable à la main) et même sur cet exemple "jouet" leur résultat n'est guère concluant ... 89% sur la lentille pratique quand avec de simple filtre façon technologie 1945 (convolution optique pour le guidage de missile) on atteindrais un 100% aisément, c'est assez mauvais...
TL;DR : l'article est une petite "preuve de concept" mais qui en pratique offre des perfs assez naze et ne résout absolument pas l'aspect qui aurait été intéressant : la conception d'un tel systeme sous sa forme matérielle. Sous sa forme actuel l'article présente un dispositif final fort peu éloigné des conception de bancs de filtres optique "had-hoc" par recuit simulé que produisent les militaires depuis des dizaines d'années ... En clair ils évacuent 99% du problème que le domaine se coltine depuis des années :
- nos équations de ce types de système en simu ne correspondent pas à la réalité suffisamment pour concevoir des suites de filtres plus élaborés
- La transmission énergétique en passif avec ce type de systeme pose un gros soucis dans la réalité (ils l'observent d'ailleurs dans la conclusion du papier)
- la modification de flux lumineux complexe dans ce type de systeme pose pas mal de gros soucis qui en atténue l’intérêt. (amplification, pertes d’énergie etc...)
Donc en attendant qu'ils aient résolu certains de ces problèmes j'ai l'impression que la porté de l'article reste assez faible...
J'attends de voir comment ils pourront résoudre le problème de la transmission de l’énergie (et donc de sa reamplification) au delà de 3 couches. Et si leur transfert simulation-> réalité survit à l'au delà de 3 couches. Sans ce dernier point ils vont devoir trouver des solutions à l'apprentissage en ligne via des composants capable de s'auto-modifier localement. Là ce sera intéressant, mais les difficultés sont bien plus élevé.Dernière modification par Nilsou ; 13/08/2018 à 02h20.


 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non