
Mesure le nombre de transistors hors SRAM associe a une modification d'archi, c'est un bon debut pour evaluer a quel point c'est un changement par rapport a la generation precedente. Ca n'empeche pas la chose d'etre difficile parce qu'elle affecte nombre de blocs et que le potentiel de deadlock est phenomenal, mais ca ne transforme pas l'archi de P6 en quelque chose de radicalement nouveau (contrairement par exemple a ce qu'AMD a fait avec ses clusters).
D'ailleurs mesure l'IPC de Nehalem sur des programmes qui hit le L1 par rapport a Penryn, ca donne une bonne idee de l'entendue des modifications d'uarch (significatives mais pas phenomenales).
Ce que j'essaye de dire est que beaucoup restent focalises sur des micro changements dans le core alors que tout le reste du die a change et que c'est tout aussi important voir plus. Ca ne veut pas dire que les changement de core ne servent a rien, juste qu'il faut maintenant regarder autour pour vraiment comprendre ce que le die en question peut faire. Effectivement les microprocesseurs x86 commencent a devenir des SoC et comme pour tous les SoC, le core n'est qu'un des elements, et pas toujours celui qui compte le plus.

Affichage des résultats 2 791 à 2 820 sur 2889
Discussion: News en tout genre...
-
02/02/2010, 19h03 #2791*X86 ADV Natif*


- Ville
- Far far away
fefe - Dillon Y'Bon
-
02/02/2010, 20h06 #2792*X86 ADV*
- Ville
- Vence
Je suis tout à fait d'accord qu'il faut considérer l'ensemble du die, souvent les gens oublient que l'équilibre d'un système déborde largement celui d'une coeur, et si déséquilibre il y a...
Je te crois tout à fait quand tu dis que les changements de Penryn à Nehalem sont mineurs, mais du coup je m'interroge sur le type d'HT implémenté ; il me paraît plutôt efficace donc a du nécessiter pas mal de modifications. Il n'y a pas aussi des changements de cycle sur les accès L1 ? Rien que ça, ça doit impliquer des modifs non triviales.
D'un autre côté, compter les transistors a peut-être un sens pour des CPU qui évoluent chez Intel, mais par exemple si on comparait le nombre de transistors d'un A8 et d'un A9, ça donnerait le résultat inverse en terme de perf J'imagine que pour toi nouvelle archi revient à partir d'un tableau blanc sur par exemple tout le contrôle.
J'imagine que pour toi nouvelle archi revient à partir d'un tableau blanc sur par exemple tout le contrôle.
-
02/02/2010, 20h56 #2793*X86 ADV Natif*
- Ville
- Far far away
Les archis Intel et AMD reutilisent enormement de blocs d'une generation a l'autre. Ils peuvent etre modifies, mais les modifications sont souvent incrementales. Regarder une photo de die peut te donner des infos sur la taille des changements. Si tu regardes 2 cores bien differents (un Alpha 21164 et un 21264 par exemple) tu ne retrouveras pas de similitude dans les blocs et faire ce genre d'exercice n'a aucun interet.
Tu n'es pas force de commencer avec une feuille blanche pour faire quelque chose qui meriterait le nom de nouvelle archi, mais en gros un schema tenant sur une feuille A4 aurait des differences significatives pour une nouvelle archi, alors que pour une evolution, tu changes juste quelque labels sur ton schema.
J'imagine que A8->A9 il y a des differences fondamentales qui empeche la comparaison bloc a bloc.
A propos d'HT, oui il est assez efficace, mais c'est plus du a l'experience de l'equipe qui l'a implemente dans le domaine qu'a la quantite de modifications. Ce dont tu as besoin essentiellement peut se resumer a quelques mecanismes d'arbitrage. Il est tres difficile de bien les concevoir, mais une fois que tu connais le probleme ce n'est pas d'une complexite dramatique.
Les connaissances necessaires a une equipe qui n'a jamais implemente de SMT pour reproduire ca sont l'equivalent d'annees d'experimentation, mais une fois les connaissances acquises ce n'est pas particulierement complique (par rapport a la complexite du reste du core).fefe - Dillon Y'Bon
-
02/02/2010, 23h35 #2794*X86 ADV*
- Ville
- Vence
Les coeurs A8 et A9 ont été développés par deux équipes complètement différentes ne partageant pas la même vision, donc il ne s'agit pas seulement de différences
")
Quant au SMT, je pensais naïvement qu'un bon SMT aurait du mal à s'intégrer dans une archi existante. Bien sûr on peut le faire à gros grain, mais là je me demande si le gain présente le moindre intérêt ; et si on doit affiner, ça doit vite devenir tricky (et donc nécessiter l'expérience dont tu parlais). Y'a des articles qui discutent de différents types d'implémentation SMT et de leur (non-)efficacité ?
-
03/02/2010, 20h19 #2795*X86 ADV Natif*
- Ville
- Far far away
Il y a des publications de recherche qui etudient localement des mechanismes pour implementer SMT plus efficacement, mais je doute qu'il y ait des articles par des equipes qui connaissent l'ensemble des problemes (parce qu'ils l'ont implemente). Je pense que ca restera des trade secrets pour un moment.
fefe - Dillon Y'Bon
-
08/02/2010, 09h31 #2796*X86 ADV*
- Ville
- Vence
simics rachete par Intel : http://www.linuxfordevices.com/c/a/N...ire-Virtutech/
Je suis surpris, je pensais qu'Intel avait ce genre de techno in-house. Ou alors c'est leur hyperviseur qui les interesse ?
-
08/02/2010, 13h45 #2797Hardc0re

- Ville
- LIEGE
AMD prévoit d'intégrer un mode turboboost sur ses futurs x6 Thuban
")
"There are not a lot of details available at this point, but what we do know is that when single-thread performance is needed most, Thuban processors will automatically disable idle cores and overclock the remaining engines to the maximum possible level that is determined by general thermal design power"
Pas encore trop de détails sur le fonctionnement ,et quid de la compatibilité avec les cartes mères actuelles ?
"It is clear that the new AMD Phenom II X6 “Thuban” processors will be compatible with AM3 and AM2+ platforms, however, we do not know whether performance booster of the six-core chip will work on all of them"
-
10/02/2010, 10h35 #2798*X86 Hitch*
Tiens, plutôt intéressant le dossier sur la 2d chez Tom hardware, Ati en prend pour son grade :
La 2D sous Windows : surprise !
-
10/02/2010, 14h45 #2799*X86 ADV*
- Ville
- Liège (Belgique)
En effet, et Nvidia n'est pas tout blanc non plus sur ses chips récents. Dingue comme le vieux IGP déclasse tout le monde ! Envoyé par Stéphane.P
Envoyé par Stéphane.P

Je me suis fait la réflexion il n'y a pas longtemps, la 2D n'est plus benchée nulle part depuis longtemps, alors que c'est quand-même ce que tout le monde utilise la toute grande majorité du temps ! Perso, dans le cadre de mon boulot, je serais interessé de pouvoir revoir des benchs 2D, ne fusse que pour voir si il n'y a pas de perte de perf, à défaut d'améliorations... cet article fait réfléchir (justement des 5000 en commande pour tester et remplacer les 4000 que nous utilisons pour le moment)
-
21/04/2010, 00h45 #2800Caneton

- Ville
- Sürkrütland
Hardware Secrets tape sur les tests d'alimentations.
Ils enfoncent des portes ouvertes en préconisant l'emploi d'un multimètre et d'un oscilloscope, mais ça a le mérite de lever le lièvre.
-
21/04/2010, 12h51 #2801*X86 ADV*

Page 7 :
"By the way if you want to compare our methodology to the one used by other leading reviewing websites, here are the links to their methodology:
AnandTech
CanardPC"
Deuxième position derrière AnandTech dans les "leading reviewing websites" sur un site anglophone... pas mal !
-
21/04/2010, 14h53 #2802*X86 ADV*
Surtout pour un site dont le nom commence par "Canard" et dont la mascotte ressemble à un lapin crétin, ça aide pas niveau crédibilité
-
21/04/2010, 15h31 #2803*X86 ADV*

- Ville
- Lorient (56)
Moi je propose qu'on renomme CanardPc en Aaaahhh!Un Canard qui parle!, comme ça, il serait en première place.
(Perso, j'adore les tests d'Hard OCP sur les alims...)There are only 10 types of people in the world: Those who understand binary, and those who don't.
-
24/04/2010, 22h21 #2804Roxx0r


- Ville
- Chaumont sur Loire
Un petit article qui compare l'ARM et le X86 en terme de performance dans le cadre de solutions embarquées. Cortex A8 (ARM) contre un Atom, un Nano et un Barton mobile (X86).
C'est ici que ça se passe et c'est en anglais.
-
26/04/2010, 16h32 #2805Roxx0r
- Ville
- Chaumont sur Loire
Nintendo renouvelle son accord avec S3 Graphics.
Cet accord porte sur le S3TC et au départ je pensais que la news avait 10 bonnes années de retard.
Cette news m'apporte à me poser des questions :
le S3TC est devenu le DXTC dans la version 7 de DX il me semble.
Donc si Nintendo utilise le S3TC au lieu et place du DXTC on peut supposer qu'il utilise une API qui n'est pas dérivée de DX ?
De même savez vous si le S3TC a évolué depuis 1999 ? Et pourquoi Nintendo n'utilise pas par exemple le FXT1 de feu 3dfx dont le code source est dispo ?
-
26/04/2010, 16h51 #2806*X86 ADV*
- Ville
- Vence
Tu crois que qui que ce soit a envie d'utiliser l'API d'un concurrent ? Qui de plus concue pour des machines autrement plus performantes ? Envoyé par Narm
Ce n'est pas parce que du code source est disponible qu'il n'y a pas de brevet associe. Bon dans ce cas precis, j'en sais rien? Et pourquoi Nintendo n'utilise pas par exemple le FXT1 de feu 3dfx dont le code source est dispo ?
-
27/04/2010, 12h36 #2807*X86 ADV*

Tout les droits ont étés récupérés par Nvidia, probable que Nvidia interdise toute utilisation commerciale sans passer à la caisse. Envoyé par newbie06
@+, Arka
-
27/04/2010, 12h46 #2808*X86 ADV*
- Ville
- Vence
http://en.wikipedia.org/wiki/FXT1
Another possible reason for its lack of adoption is that the CC_MIXED mode (see below) probably infringes the S3TC patent (US Patent 5,956,431).
-
27/04/2010, 13h18 #2809*X86 ADV*
Et je viens de vérifier, ce brevet est toujours valable. (sérieusement, il faut que l'USPTO améliore l'intégration de ses outils, trouver la moindre info est une horreur) Envoyé par newbie06
@+, Arka
-
27/04/2010, 14h44 #2810Roxx0r
- Ville
- Chaumont sur Loire
Merci à vous deux d'avoir éclairer ma lanterne
Je suppose que connaître les termes du contrat est presque impossible : je voudrais bien savoir combien touche S3G sur chaque console vendue, à moins que cela ne soit une "licence globale"...
-
27/04/2010, 15h33 #2811*X86 ADV*
Connaitre les termes d'un contrat est effectivement généralement impossible (les sociétés qui les signent s'amusent rarement à les rendre public). Envoyé par Narm
Par contre, il est normalement possible de connaitre, sinon les détail financier, du moins l'existence des licences de brevets, qui doivent être déposés auprès de l'INPI (oui, je parle uniquement de la France, mais ça doit pas être trop différents ailleurs) pour pouvoir être opposable aux tiers.
@+, Arka
-
27/04/2010, 19h30 #2812*X86 ADV*

Sandy Bridge promet d'être un monstre en débit d'IO, sur à peu près toute la gamme :
http://pc.watch.impress.co.jp/docs/c...28_364200.html
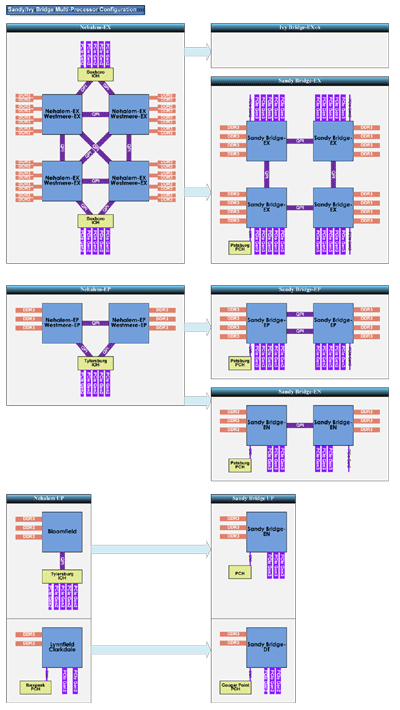
À votre avis, pourquoi cette débauche de bande passante sur les plateformes serveur?
- Pour du stockage (SSD)?
- Du réseau (genre Infiniband)
- Des GPU?
Par contre, le QPI a beau passer à 7.2 ou 8 GT/s au lieu de 6.4, ça semble un peu déséquilibré entre comm interne et externe... Y'a intérêt à bien gérer l'affinité par rapport aux IO, sinon gare aux effets NUMA.
Espérons que les bios/chipsets/drivers soient moins buggés pour gérer les transferts PCIe qu'avec Tylersburg.
-
27/04/2010, 19h57 #2813Randy 2016

Je crois que les serveurs ne manquent plus trop de puissance CPU depuis un moment. Par contre, on peut imaginer toutes les puces additionnelles en soutien dans les (rares) cas où ça arrive.
Je trouve surprenant, moi aussi, la disparition de liens QPI. Les archi token, je sais pas ce que ça donne, mais intuitivement je dirais que ça nuit à la com CPU#1 CPU#4...
Pour l'énorme BP en plus, on peut aussi imaginer les SSD Ram qui encaissent une tétramontagne d'iops.Mes propos n'engagent personne, même pas moi.
-
27/04/2010, 20h50 #2814*X86 ADV*
Si je me gourre pas, sur un Sandy Bridge EX, chaque socket aurait (upload+download cumulé):
- 51,2 Go/s de DRAM locale
- 80 Go/s de PCIe
- 64 Go/s de QPI
Contre :
- 34,1 Go/s DRAM
- 25,6 Go/s QPI vers chipset et 18 Go/s de PCIe
- 76,8 Go/s QPI vers les autres sockets
pour un socket de Nehalem EX
Donc ce n'est pas si flagremment déséquilibré que ça entre DRAM et QPI... C'est plutôt sur Nehalem-EX que le QPI était surdimensionné.
Sinon l'hypothèse de la DRAM sur PCIe est intéressante. Si la quantité de RAM compte plus que la puissance de calcul ou la latence, ça permettrait d'ajouter des pelletées de RAM, tout en gardant un CPU réutilisable sur supercalculateur avec réseau très haut débit et GPU.
A priori pas besoin de contrôleur genre SSD, la mémoire PCIe ça se mappe bien directement de façon cohérente il me semble?
-
27/04/2010, 22h48 #2815Randy 2016
Euh, PCI-e = série et DDRx = //
Du coup, sans contrôleur, ça me parait difficile.Mes propos n'engagent personne, même pas moi.
-
27/04/2010, 23h08 #2816*X86 ADV*
Je veux dire, pas besoin d'émuler un disque dur pour rendre la mémoire accessible à l'OS comme avec un SSD. La mémoire accédée à travers le PCIe peut être mappée en mémoire physique pour que le CPU y accède directement. Au niveau logique.
Après le hardware se démerde pour router et maintenir la cohérence. Et gérer les 15 couches de la norme PCIe d'un côté et les 44 modes d'opération de la DDR3 de l'autre...
-
28/04/2010, 01h46 #2817*X86 ADV Natif*
- Ville
- Far far away
Le probleme est que dans mes souvenirs la memoire mappee sur les addresses IOs n'est pas cachable, donc ce n'est pas particulierement une bonne idee d'adresser ta memoire directement sur le PCIe, par contre ca fait du swap tres rapide.
fefe - Dillon Y'Bon
-
28/04/2010, 10h57 #2818*X86 ADV*
J'ai l'impression que c'est juste une décision du développeur de bios/driver de rendre la mémoire mappée IO non-cachable (vu que par définition d'IO, on cherche à transmettre des données, donc les garder en cache n'est pas super intéressant, et le périphérique à l'autre bout du bus n'est pas capable de snoop...)
Mais je ne trouve rien d'écrit dans la doc (vol. 3 ch. 10, verset 3) qui empêcherait de le faire, et je ne vois pas non plus de raison technique qui ferait que ça ne marcherait pas (moyennant support du bios et de l'OS)...
-
28/04/2010, 14h01 #2819*X86 ADV*
- Ville
- Vence
J'irai meme plus loin :
Vol 3, 3.7
Donc on peut avoir les caches allumees sur des zone I/O.Page-level cache disable (PCD) flag, bit 4
This flag permits caching to be disabled for pages that contain memory-mapped I/O ports or that do not provide a performance benefit when cached.
(C'est la premiere fois que je regarde la MMU d'un x86. Dorenavant j'arreterai de dire que la MMU ARMv7 est compliquee.)
-
28/04/2010, 19h13 #2820*X86 ADV Natif*
- Ville
- Far far away
Le fait que le mode cacheable pour les IO existe ne veut pas dire qu'il est performant etant donne que l'essentiel des IOs sont non cacheables aujourd'hui (les flots de coherence peuvent etre lents sans que ca impacte qui que ce soit).
fefe - Dillon Y'Bon

 Répondre avec citation
Répondre avec citation
 Règles de messages
Règles de messages
- Vous ne pouvez pas créer de nouvelles discussions
- Vous ne pouvez pas envoyer des réponses
- Vous ne pouvez pas envoyer des pièces jointes
- Vous ne pouvez pas modifier vos messages
- Les balises BB sont activées : oui
- Les smileys sont activés : oui
- La balise [IMG] est activée : oui
- La balise [VIDEO] est activée : oui
- Le code HTML peut être employé : non